
记一个韩文字符规范化的坑
目录
NLP 中,经常要对字符串进行预处理,再送给模型。常在河边走,哪能不湿鞋。这不前段时间就因为这个预处理,出了大问题。
一切都乱了
我们做的是新闻处理,会涉及新闻分类、去重等操作。国庆假期回来,同事反馈,韩语的内容分类,一下全都不对了!全都被分到了某几个分类中。
怎么回事
我们有个 embedding 服务,负责给输入的文本生成向量,以备后面给其他服务使用,比如向量搜索。这个服务是支持多语言的。有天我在休假中,领导发来消息说发现同一文本的全角和半角形式,相似度比较低。我上线看了下,确实是,当时想这也太傻了。不过解决不复杂,直接统一转成半角形式就行了。
搜了下,网上大部分是硬编码的形式转的,固定范围的 unicode 码位减去一个常量就得到了相应的半角形式。我觉得不太优雅,想到了 unicodedata 这个库,当时 bert tokenizer 还用这个库来规范化文本,用的是 NFD,我所用的模型又是 bert 系的,所以我就直接用了 NFKD。由于是在日文上发现的,所以我也测试日语上的效果,以及中文、阿拉伯文等。没什么问题,就更新了。
结果后来问题就出来了。NFD 在韩语上有大问题,韩语向量一下就全不对了。
Unicode 规范化
为了能够比较任意两个字符串是否等价,具体来说就是二进制是否相等,有了规范化形式(Normalization Form)这个概念。有很多字符看起来的样子和它实际的样子是不一样的,比如带有重音字符的字母,看起来是一个字符,但实际上是由重音字符和相应字母组成的。
Unicode 文本有 4 种规范化方法,这 4 种方法区别在于使用哪种分解方法(canonical decomposition 和 compatibility decomposition)以及是否进行组合:
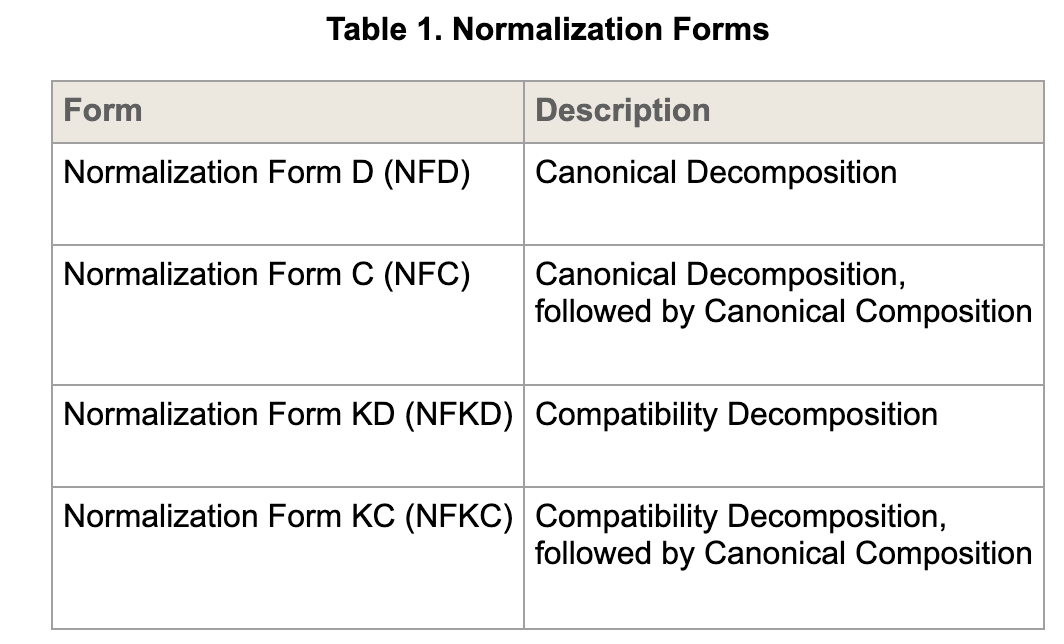
compatibility 这个单词中明明没有 K,那为什么是 KD 和 KC 呢?这是为了避免 compatibility 的 C 与 canonical 和 composition 的 C 混淆,所以用了 K 来指代 compatibility。
分解方式有两种:canonical decomposition 和 compatibility decomposition,也就是有无 K 的区别。两种分解方式都是将字符串分解为他们的等价形式,前者的分解结果,在外观上尽量与原始字符串一致(这里的一致指的是在字符串被正确渲染时,看起来是一样的),语义上也是一致的。而后者则是忽略外观,只找到语义上等价的字符串。典型的兼容分解有:
- 全角转半角。
- 上下标转成普通数字字母,比如上标 $^2$ 转成普通的 2。
简单来说,带 C 的都多一个组合的步骤,带 D 的都只有分解步骤,带 K 的都会进行兼容性处理(比如全角转半角、上下标转为对应的字母数字)。
以下是几个示例:
1 | In [24]: def normalize(text: str): |
韩语怎么特殊了
我们再来看两个例子:

前面不是说了尽量保持外观一致吗?怎么韩文这里看起来完全变了呢?下面的 e 就没问题(虽然实际上也是被分解成了两个字符)。那是因为:
There are also special rules to fully decompose Hangul syllables.
韩文就是这么特殊,韩文是由音节组成的,没错,就是类似我们的拼音,所以他们是直接用拼音写字的。具体来说,가 是一个预组合的韩文字符,由以下部分组成:
- 初声:ᄀ (U+1100, HANGUL CHOSEONG KIYEOK)
- 中声:ᅡ (U+1161, HANGUL JUNGSEONG A)
所以会看到被分开了。但是如果你把输出复制到网页上,也就是 '가' ,你就又发现,看起来好像又一致了,这就是上面说的渲染的问题。
而韩文的 NFKD 和 NFD 的结果是一样的,所以就导致所有韩文都被分解成他们的音节了,导致 embedding 模型出错,几乎全都判成相似了。比如下面的两句话:
1 | sents = [ |
可以看到原始句子的相似度很低,这是正常的,然而 NFD 规范化后,相似度都快到 1 了。