日常开发的时候,我们可能经常需要同时运行或维护多个程序(服务),时间一长可能就记不住了,运行命令都不一定能记得。而且一旦服务器崩了或者其他意外情况,这些服务还得手动去启动,很是麻烦(当然你也可以使用 init 等来设置开机自启)。这时就需要一个页面来统一管理了。
Supervisor 登场!
Supervisor 是一个用于管理和监控进程的工具,使用 Python 开发,可以确保在出现意外情况时,进程能够持续运行,并在失败后自动重启,通常用于监控服务器进程,如 Web 服务器和应用程序服务器。
Pros:
- 自动重启:当进程意外退出或崩溃时,Supervisor 会自动重启进程,确保进程持续运行,减少因意外情况导致的服务中断时间。
- 监控和日志:Supervisor 可以监控进程的状态,并提供详细的日志和报告。
- 配置简单:配置文件采用 INI 格式,使用简单,可以根据需要定义进程的启动命令、运行参数、日志路径等。
- 多进程管理:Supervisor 可以同时管理多个进程,可以方便地添加、删除和管理多个进程。
- Web 界面:Supervisor 提供了一个简单易用的 Web 界面,用户可以通过浏览器直观地查看和管理进程,包括启动、停止、重启和查看日志等操作。
Cons:
- Web 界面过于粗糙,只有启停、查看日志等操作,进程 CPU 占用、内存使用等都没有。
不过说起来这是我第二次使用 supervisor 了,第一次还是几年前,东西都忘了。这次使用的时候查了好多资料才正常跑起来,所以为了方便下一次使用,以及有需要的同道们,特此记录一下,后面有什么新的需要记录的再更新。
安装
Supervisor 是一个 python package,所以对 pythonista 来说,安装方式再熟悉不过了:
1 | pip install supervisor |
配置
配置文件用来配置 supervisor 本身的一些设置以及你要添加的程序,一般叫 supervisord.conf 。如果你启动的时候没有用 -c 来指定配置文件的地址,那么 supervisor 会自动按照以下顺序来寻找:
../etc/supervisord.conf(Relative to the executable)../supervisord.conf(Relative to the executable)$CWD/supervisord.conf$CWD/etc/supervisord.conf/etc/supervisord.conf/etc/supervisor/supervisord.conf(since Supervisor 3.3.0)
可配置项很多,我一般不会从头写,都是基于默认配置来修改。我们可以用 echo_supervisord_conf > supervisord.conf 来将默认配置写到 supervisord.conf 中。
如果在语句后直接添加注释,那么必须与语句隔一个空格。比如
❌ "a=b;comment"
✔️ "a=b ;comment"
下面我就讲下和默认配置不一样的地方。
inet_http_server
1 | [inet_http_server] ; inet (TCP) server disabled by default |
这个 section 与后面的 web 界面以及 supervisorctl 与 supervisord 的通信有关。默认是只能本地连接(localhost),而且没有用户名密码,如果需要从其他服务器上访问 web,那么则需要使用 * 来指定允许所有 ip 访问。为了安全考虑建议设置用户名密码。
supervisorctl
1 | [supervisorctl] |
这里就是配置 supervisorctl 与 supervisord 通信的地方。主要是 serverurl (端口)与用户名密码需要和上面配置的一致,否则会出现拒绝链接或者认证失败的错误。
program:x
1 | [program:your_program_name] |
这个 section 就是重头戏了,我们在这里配置需要启动的程序,一个配置文件可以有多个这个 section。
[program:your_program_name]:your_program_name就是你的程序名字,想叫什么就叫什么,别太离谱就行。command:你的程序的执行命令,你平常怎么执行的这里就怎么写,但是 executable 最好写绝对地址,比如你用python app.py来执行程序,那么这个python最好写成绝对地址,尤其你有多个 python 环境时。你可以用which python来查看绝对地址。process_name:默认就是程序名(your_program_name),这个名字会在 web 界面上显示。directory:指定运行时需要 cd 到的目录(工作目录),也即你的程序文件所在的目录。autostart:是否在 supervisord 启动时启动程序。autorestart:是否在程序退出时自动重启。有三个值可选:false:不自动重启。unexpected:默认值。当 exit code 不在预料之内时,重启。什么叫不在预料之内?这个值是由exitcodes指定的,默认为 0。true:无论如何都自动重启。
redirect_stderr:是否将 stderr redirect 到 stdout。stdout_logfile:stdout 日志文件。stdout_logfile_maxbytes:单个日志文件的最大大小。stdout_logfile_backups:保留多少份日志文件。
启动
1 | supervisord -c supervisord.conf |
更新配置文件
当我们更新了配置文件后,需要让 supervisor 也更新一下,我在网上查到的说是需要先 reread 再 update,但是我查询了文档,文档是这么写的:
reread:
Reload the daemon’s configuration files, without add/remove (no restarts)
update:
Reload config and add/remove as necessary, and will restart affected programs
很明显 update 已经做了 reread 的工作,而且还会 restart。
所以更新配置文件后,只需执行 update 即可更新 supervisor:
1 | supervisorctl update |
如果你的配置文件移动了位置,那么需要重启 supervisord:
- 查询 supervisord PID:
supervisorctl pid。 - 杀死 supervisord 进程:
kill supervisord_pid。 - 用新配置文件启动 supervisord:
supervisord -c new_supervisord.conf。
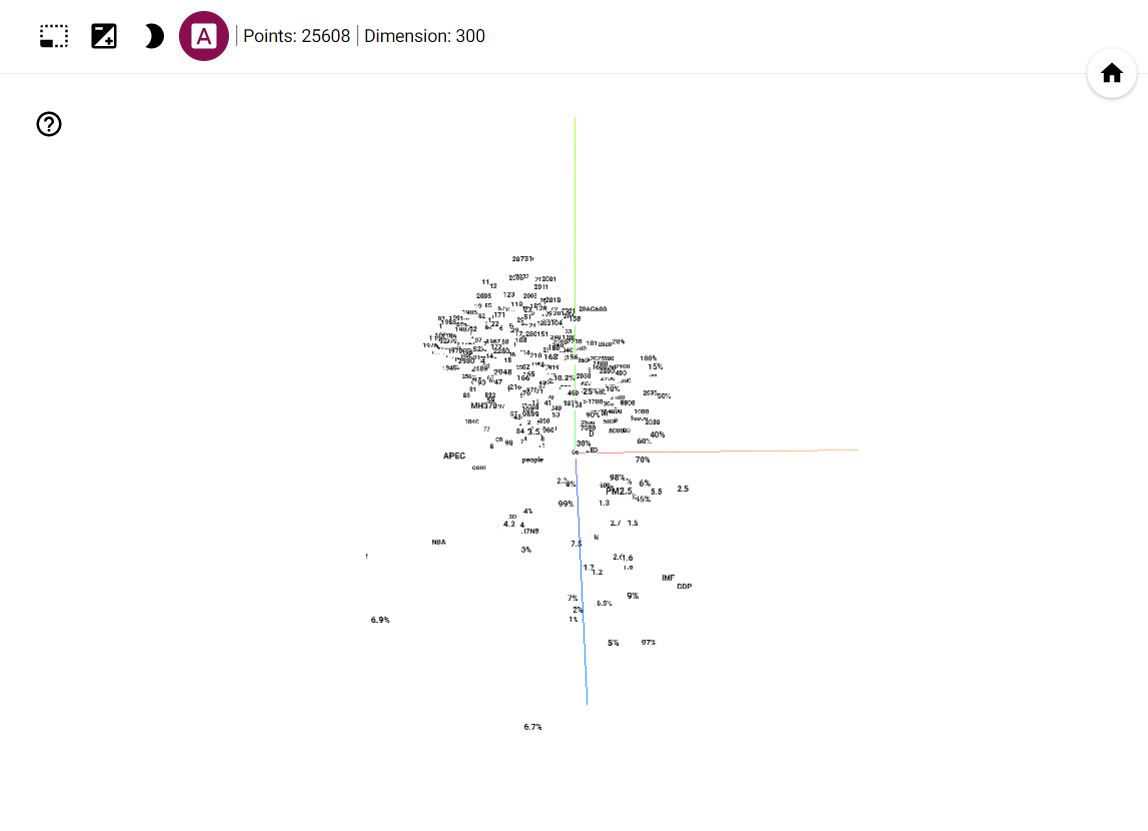
Web 管理界面
前面提到过有一个 web 管理界面,根据 inet_http_server 的配置,使用相应的 ip 和端口在浏览器上访问即可,默认是 9001 端口。界面样式如下:
 Supervisor web 管理界面。
Supervisor web 管理界面。在这个界面上可以看到所有已配置程序的状态,可以启停和查看日志,直接点击 Name 列可以查看最后几行的日志,而点击 Tail -f * 可以看到实时日志,不过这个在我这里特别慢,不知道为社么。
supervisord 与 supervisorctl
刚才我们用了 supervisord 和 supervisorctl 两个命令,你可能会疑惑这两个有什么区别。其实我们一般使用的时候,用前者启动 supervisor 主程序,用后者来管理我们自己所添加的 program。所以 supervisord 就像个后台的 server,而 supervisorctl 是一个前台的 client,有很多 action(subcommand)可以执行,比如上面的 update 和 reread 就是两个 action。而 supervisord 是没有的。
supervisorctl 常用的 action 有:
status:查看 program 状态。update:更新配置文件并重启相关 program。pid:获取 supervisord 的 PID。
其他不是很常用,感兴趣的可以去文档查看。