
TensorBoard Projector 简易指南
目录
TensorBoard(TB)是一个非常棒的模型可视化工具,早期我也写过一篇文章来详细介绍各个面板。
不过士别三日,当刮目相待。现在的 TB 和那时相比变化太多了,增加了许多功能面板,绝大部分我都还没怎么用过。其中最吸引我的面板之一就是 Projector,虽然我现在工作中并不怎么用到。
现在终于抽出时间,来完整体验并写一篇 TensorBoard Projector(TBP)的简易教程。
本文将会从原始文本出发(中文),经过训练 embedding、生成所需文件等步骤,一步一步,最终使用 TBP 来可视化 embedding,并解决中文标签不能显示的问题。
我们先来看下最终效果:
 Embedding Projector
Embedding Projector虽然说现在 BERT 等预训练模型大行其道,但我还是想从更“复古”的词向量出发。当然如果你想使用 BERT 来生成 embedding,也是完全没有问题的,框架是相同的。
此外,这个过程和你所使用的库无关,无论你是 Numpy、Scipy 还是 TensorFlow、PyTorch,只要能够得到 embedding 向量,那就都没有问题。
使用 TBP 可视化 embedding 的基本逻辑是很简单的:
- 得到一些词及其 embedding。
- 将他们按照 TBP 认可的对应关系放到文件中。
- TBP 读取文件并可视化。
相应的我们需要下列文件:
- 原始文本和 embedding 模型:用以得到词及其 embedding。
metadata.tsv、tensor.tsv和sprite.jpg:分别用于存放词、embedding 和词对应的图片(当然也可以是 PNG),最后一个用于解决中文标签不能显示的问题。projector_config.pbtxt:用于告诉 TBP 上述文件的位置以及其他配置。
下面我们就来一步一步看如何得到这些文件。
词及词向量
原始文本来自习大大的讲话数据库,使用 spacy 分句,共得到约 38 万句子。然后使用 jieba 和自定义词典进行分词,得到 tokenized_sents.txt,该文件格式是一行一个分词后的句子,词之间空格分隔。词向量使用 gensim 的 fasttext 模型训练得到,维度 300。为减少词的数量,去掉停用词。
1 | # Train embeddings |
metadata.tsv 和 tensor.tsv
metadata.tsv 的常见格式有两种:没有表头,只有一列;有表头,有两列。前者(格式 1)就是 NLP 中常见的 vocab.txt 的格式,一行一个词。后者(格式 2)的两列一般表示 index 和 label。label 就表示该样本所属的标签,一般多见于分类数据集。实际上格式 1 是格式 2 的特例,相当于默认认为其行号就是 index,行内容就是 label。
metadata.tsv也可以有多列,多出来的列可以用来表示其他属性信息。
tensor.tsv 用于存储与 metadata.tsv 对应的 embeddings。顺序必须一致,即 metadata.tsv 中第 i 行的词,其 embedding 也必须是 tensor.tsv 中的第 i 行。embedding 中数字用 \t 分隔。
接上,我们得到模型后,使用其得到的 vocab 及对应的 embedding 来生成这两个文件:
1 | stopwords = Path("hit_stopwords.txt").read_text(encoding="utf8").splitlines() |
sprite.jpg
正如开头给出的效果图一样,图中每个点都是有一个 label 的,这个 label 就是词。如果我们直接这样启动 tensorboard,会看到如下页面:
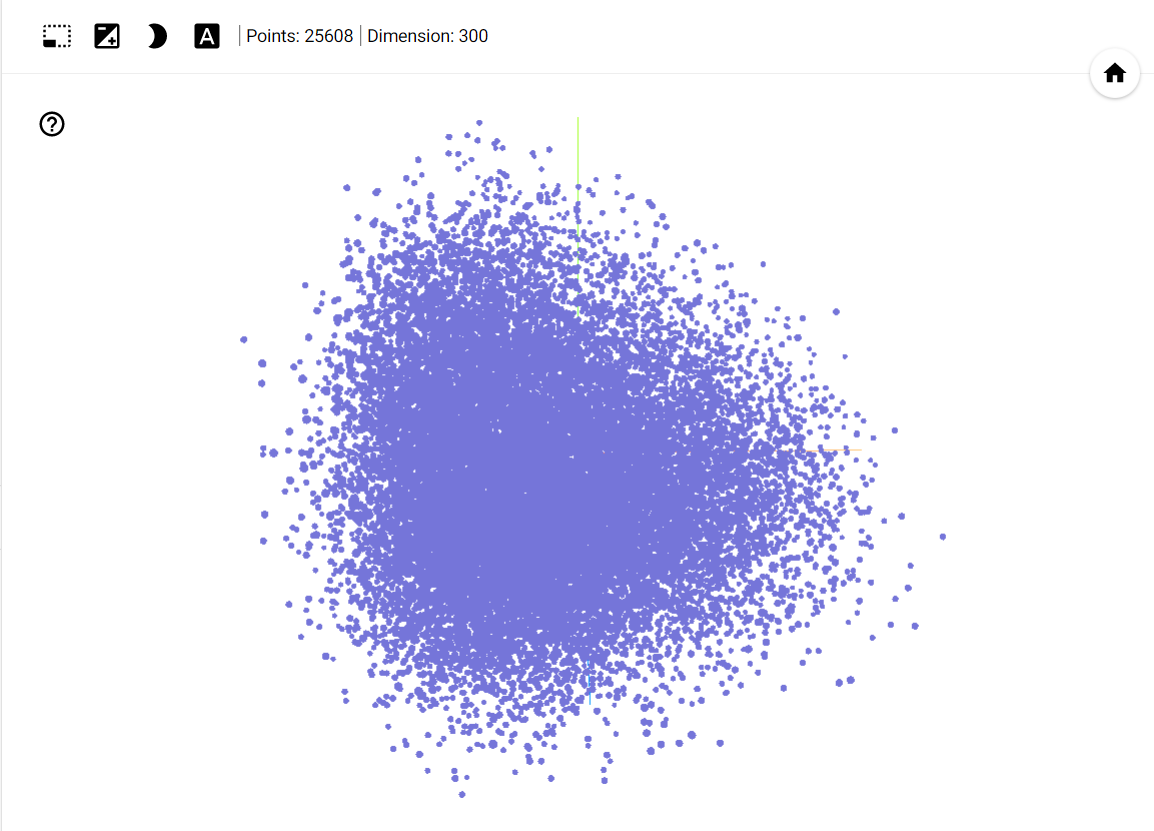 Projector 默认页面,不显示 3D 标签
Projector 默认页面,不显示 3D 标签但启用 3D 标签模式的话,我们将会看到下图所示的样子:
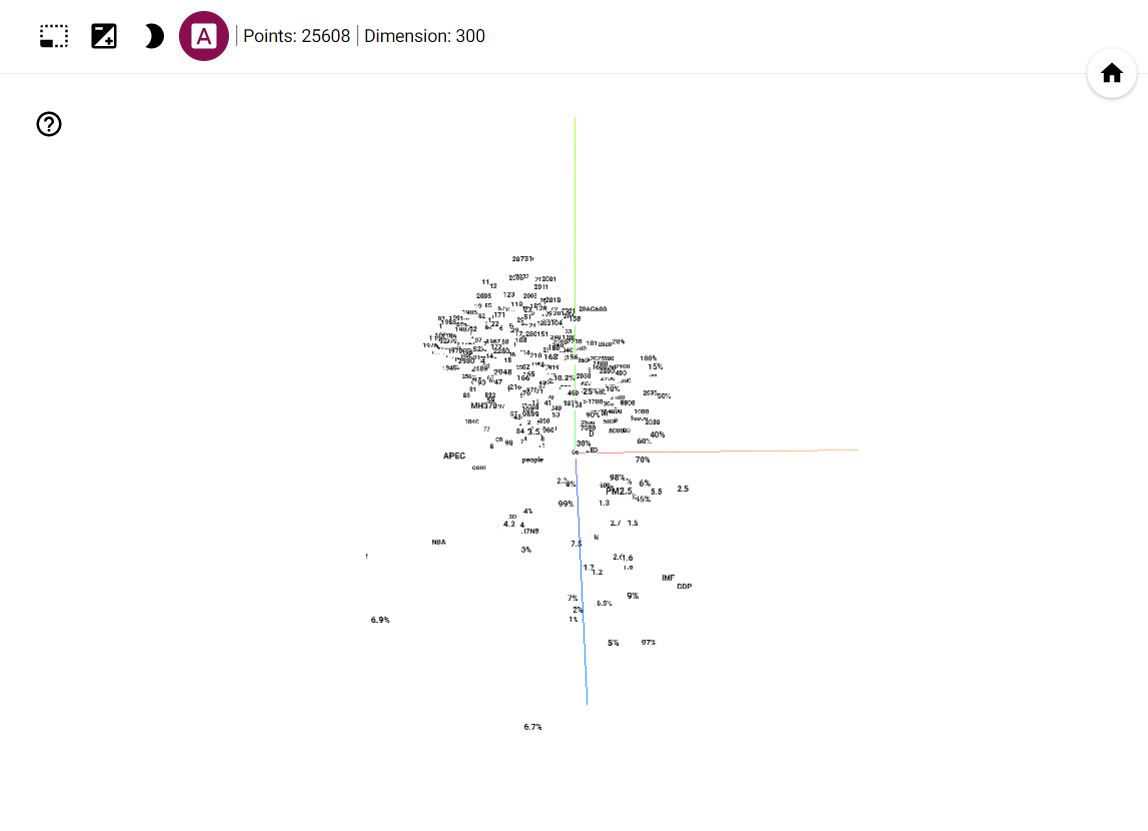 点击左上角的“A”开启 3D 标签模式后
点击左上角的“A”开启 3D 标签模式后我们可以看到所有的中文词都不见了,只剩下了数字字母等标签。
这是因为 tensorboard 目前还不支持所有 Unicode 字符标签,只支持 ascii 字符。
BUT!关闭 3D 标签模式后,如果你点击其中一个点,你会惊奇地发现又能显示中文标签了:
中文标签又回来了
一个 workaround 是将汉字转成图片,用图片来作为 label,就像官方给出的 mnist 例子一样:
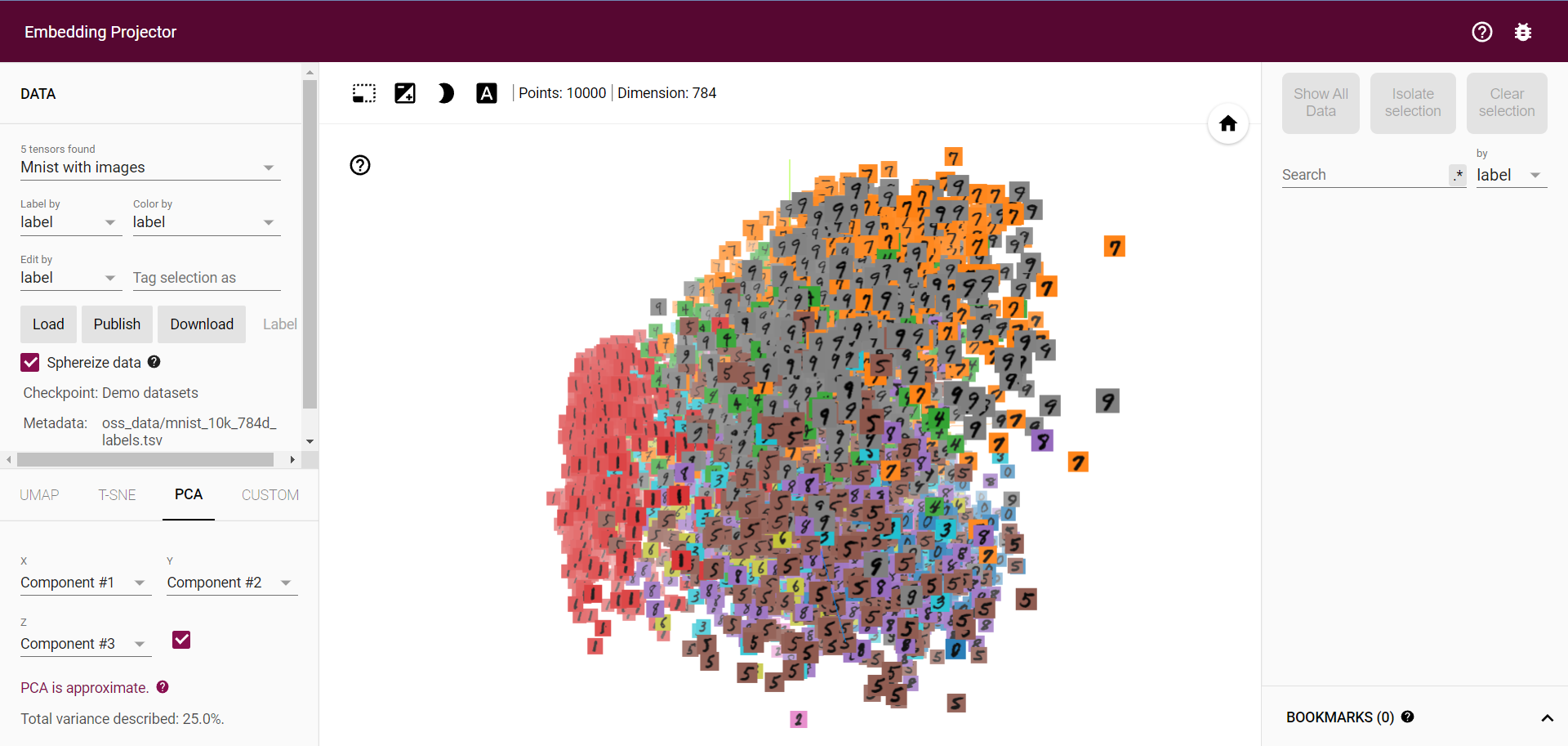 官方 Mnist 例子
官方 Mnist 例子但是由于每个词所含字的数量都不同,同时又需要尽量让词铺满整个图片,所以不同图片中字的 fontsize 都是不同的,需要视情况调整,这是一个迭代的过程。而转图片我们可以借助 PIL 来完成:
1 | def text2image(text, imgfile): |
当我们把所有词都转成图片后,再将这些图片,按照一定规则拼接到一起,最终形成的这么一个大图,就是所谓的 sprite.jpg。
 Sprite Image
Sprite Image那么按照什么规则来拼接呢?
sprite.jpg 必须是正方形,每个小图也最好是正方形,意味着行列上的小图数量必须是相等的,而且 tensorboard 读这个 sprite 的时候是按照行优先的顺序读的。所以假设你有 8 张小图,那么最终的摆放顺序就是下面这样:
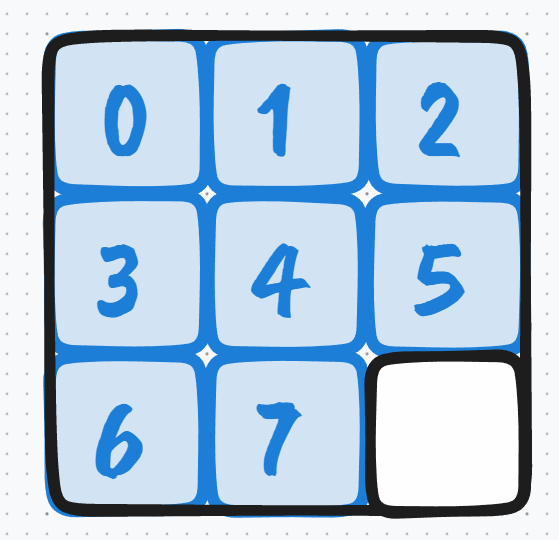 8 张小图时的摆放顺序
8 张小图时的摆放顺序最后那一格是空白的,也就是全白。
当然也有可能最后一行都是空白的,例如你有 5 张小图,那么要想每行每列上的小图数量是一样的,那么每行每列上就得有 3 张小图:
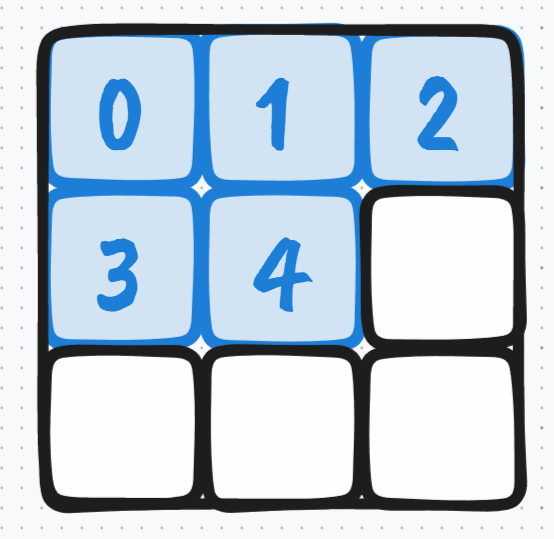 5 张小图时的摆放顺序
5 张小图时的摆放顺序这样不仅第二行最后一格是空白的,就连第三行整行都是空白的。
所以总结来说,假设你有 $n$ 张小图,那么每行每列上小图的数量就是 $\lceil \sqrt n \rceil$,即根号 $n$ 然后上取整。
具体代码如下:
1 | def text2image(text, imgfile): |
projector_config.pbtxt
在得到了 metadata.tsv 、 tensor.tsv 和 sprite.jpg 后,我们还需要告诉 tensorboard 这些文件的位置和每个小图的维度,所以我们需要一个 .pbtxt 文件来指定这些信息。
我们可以用以下程序来生成该文件:
1 | from tensorboard.plugins import projector |
然后就会得到一个名为 projector_config.pbtxt 的文件,文件内容如下:
1 | embeddings { |
当然你也可以按照这个格式直接手动创建这个文件。
启动
万事俱备,只欠东风。
现在我们终于可以启动 tensorboard 了:
1 | $ tensorboard --logdir=projector/ |
projector/就是你上面指定的logdir。
然后根据提示在浏览器打开 http://localhost:6006/#projector 就可以看到页面了,你可以在这里尝试不同降维算法的效果,也可以点击或搜索图上的词来查看其相似词,大致评估下 embedding 的效果。
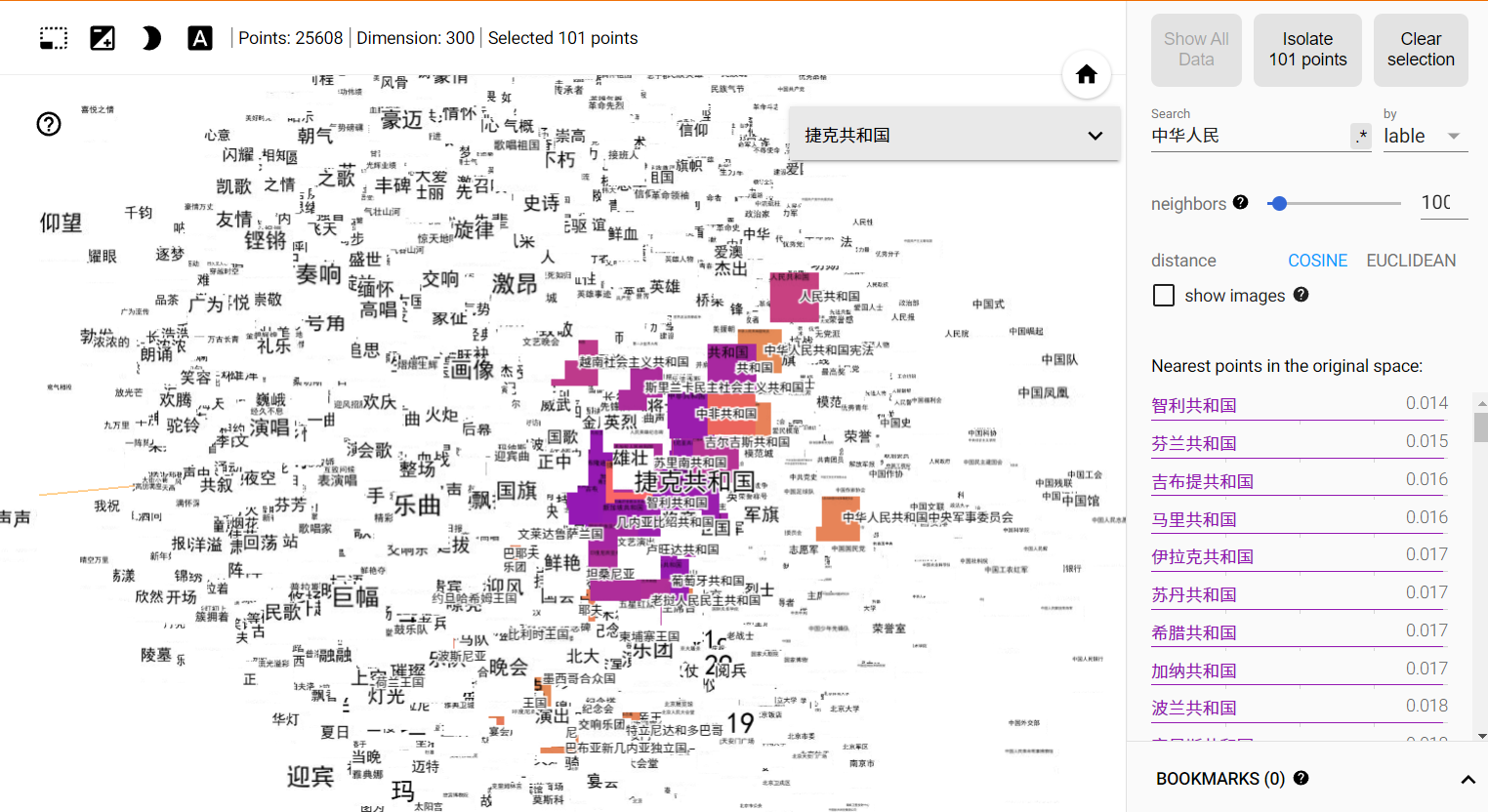 “捷克共和国”的近义词
“捷克共和国”的近义词扩展
Embedding Projector 中的点不仅仅可以是图像、词,理论上只要是可以 embedding 的东西,就可以显示。而且你懂的,万物皆可 embedding……😂
Reference
- Taking the TensorBoard Embedding Projector to the Next Level | Towards Data Science
- Visualizing Image Feature Vectors through TensorBoard | by Takuma Yamaguchi (Kumon) | Medium
- TensorBoard: Embedding Visualization · tfdocs
- Projector plugin hangs with “Fetching sprite image…” · Issue #3840 · tensorflow/tensorboard
- [projector] unicode not supported for 3D mode labels · Issue #386 · tensorflow/tensorboard
- python - PIL how to scale text size in relation to the size of the image - Stack Overflow