
pandas 读取合并单元格并保留合并信息
目录
前言
当我们使用 pandas 的 read_excel 方法读取 Excel 文件时,我们可能会遇到一个很棘手的问题:如何正确读取包含合并单元格的 Excel 表格。如果我们只是用原先的 read_excel 方法读取,那么合并单元格的信息将会丢失,从而导致我们的数据出现重复或缺失的情况。我看了下网上的文章几乎都没有很好的解决办法,大部分都是用 fillna 之类的方法去填充,很明显这是不行的,下面我会举例说明。唯一看到一篇方向正确的文章,但是却稍显繁琐,还要先存一个中间文件再读取。
在本篇文章中,我们将会探讨如何使用 pandas 正确地读取包含合并单元格的 Excel 表格,简单高效全面,同时支持 xlsx 和旧格式 xls。
本篇文章使用两个内容相同、格式不同的文件来演示说明。内容截图如下:
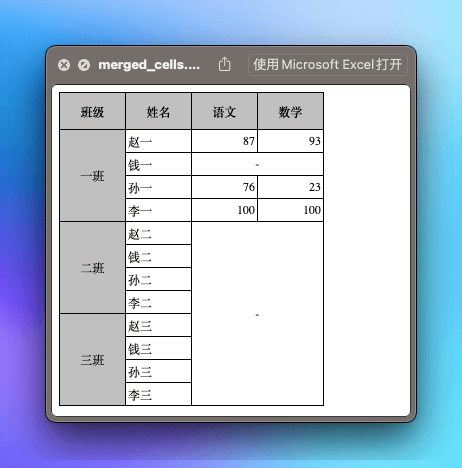 样例文件
样例文件可以看到里面有纵向合并(一班、二班、三班),有横向合并(钱一的语文和数学),也有横纵合并(二班三班的语文数学)。
fillna 的问题
当我们直接使用 read_excel 读取时,会变成下面这个样子:
 填充失败
填充失败可以看到合并单元格没有被正确填充,除了第一个单元格外其他都是 NaN ,而我们期望的是它们都用相同值填充。
当然我们可以使用 fillna 来实现,不过该方法只能是“具体情况具体分析”,横向、纵向、横纵合并单元格的情况都要根据情况用不同的 fill method,在这里我们至少需要分三种情况来进行处理,显得非常繁琐。一旦变了表格,你的代码就得变,普适性太差。
按理说,Excel 本身应该保留了合并单元格的信息,比如哪些单元格被合并了,它们的值是什么。应该存在一种工具可以读取出这种信息。
So,这就是 openpyxl 和 xlrd 派上用场的时候了。
Solution
pandas 内部实际上也是用的这两个包。根据官方文档:
enginestr, default None
If io is not a buffer or path, this must be set to identify io. Supported engines: “xlrd”, “openpyxl”, “odf”, “pyxlsb”. Engine compatibility :
• “xlrd” supports old-style Excel files (.xls).
• “openpyxl” supports newer Excel file formats.
• “odf” supports OpenDocument file formats (.odf, .ods, .odt).
• “pyxlsb” supports Binary Excel files.
Changed in version 1.2.0: The engine xlrd now only supports old-style.xlsfiles. Whenengine=None, the following logic will be used to determine the engine:
• Ifpath_or_bufferis an OpenDocument format (.odf, .ods, .odt), then odf will be used.
• Otherwise ifpath_or_bufferis an xls format,xlrdwill be used.
• Otherwise ifpath_or_bufferis in xlsb format,pyxlsbwill be used.
New in version 1.3.0.
• Otherwiseopenpyxlwill be used.
Changed in version 1.3.0.
简单来说,默认情况下(engine=None):
- 如果是 OpenDocument 格式的文件,那么使用 odf 解析。
- 如果是 xls 格式,那么使用
xlrd解析。 - 如果是 xlsb 格式,那么使用
pyxlsb解析。 - 其他格式都使用
openpyxl解析。
原先这些包是可以读取合并单元格这种格式信息的(虽然文档很不完善),但是经过 pandas 后不知道怎么回事就没了。所以这里我们就显式地用这些包来读取和操作。
总体思路就是:
- 用相应的方法读取 Excel 文件,得到 workbook。
- 根据 sheet name 取 sheet。
- 解析这个 sheet,得到 dataframe。
- 获取合并单元格及值和范围。
- 根据范围,在 dataframe 中设置相应值。
完整代码如下:
1 | import pandas as pd |
我们再次用这两个函数读取一下示例文件:
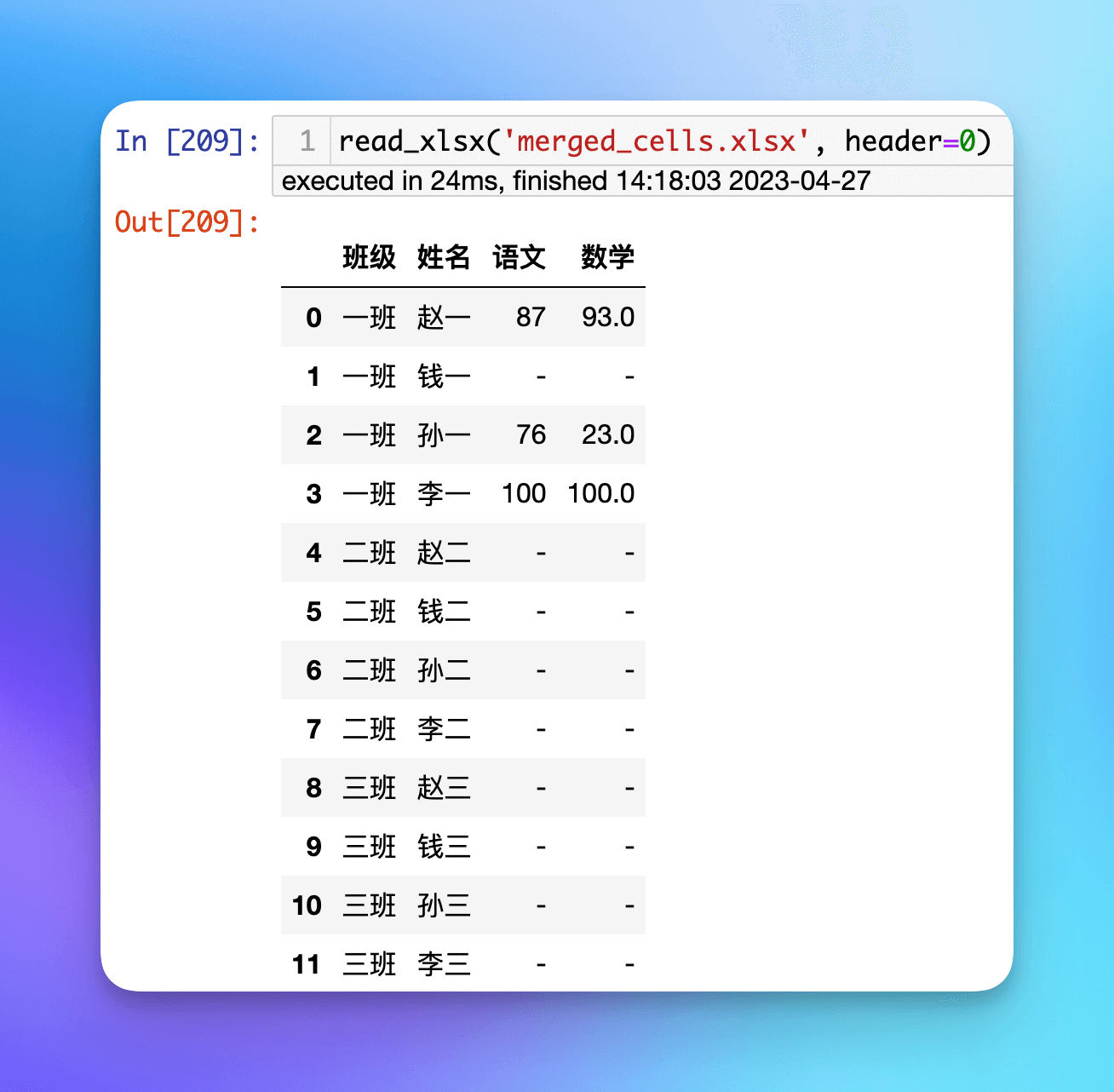 读取 xlsx 格式文件。
读取 xlsx 格式文件。 读取 xls 格式文件。
读取 xls 格式文件。可以看到 xlsx 和 xls 格式文件都能正确读取,同时支持指定 sheet name 和 header。
需要注意的问题
- 如果原先的合并单元格内容为空,那么
openpyxl的结果会是None,而xlrd仍然是空字符串。 openpyxl的merged_cells方法似乎在文档中并未出现,忘记了在哪看到的这个方法。