
为什么我的 client CPU 和 server GPU 都很闲?
目录
问题
前段时间我在跑数据批处理任务时,发生了一件怪事:client 部署在 CPU 服务器上,server 部署在 GPU 服务器上(模型),client 处理过程中会向 server 发请求。执行了一段时间后通过监控发现,client 这边的 CPU 和 server 这边的 GPU 利用率都不满,client 那边几乎可以忽略不计,server 那边只有 40% 左右。这是为什么?谁在消耗时间?正常情况下 server 应该是满的。
尝试和解决
先来大致说下数据批处理流程。流程分为两部分:client 和 server。client 主要负责整个数据处理流程,其中包括向多个模型服务发起请求,不涉及 GPU,部署在 CPU 服务器上。server 就是模型服务,部署在 GPU 服务器上,负责 load 模型和 inference。开始处理的时候,会临时起多台 GPU server,然后上面加一层负载,client 就用这个负载地址来请求 server。
那天在启动任务开始处理的时候,已经有其他任务在用 server 了,而且是同一个负载地址。我们在启动这个新任务的时候,为了满足计算需求,直接往这个负载下加了 10 台 GPU server。然后启动 client,任务开始。
启动后 client 的情况:
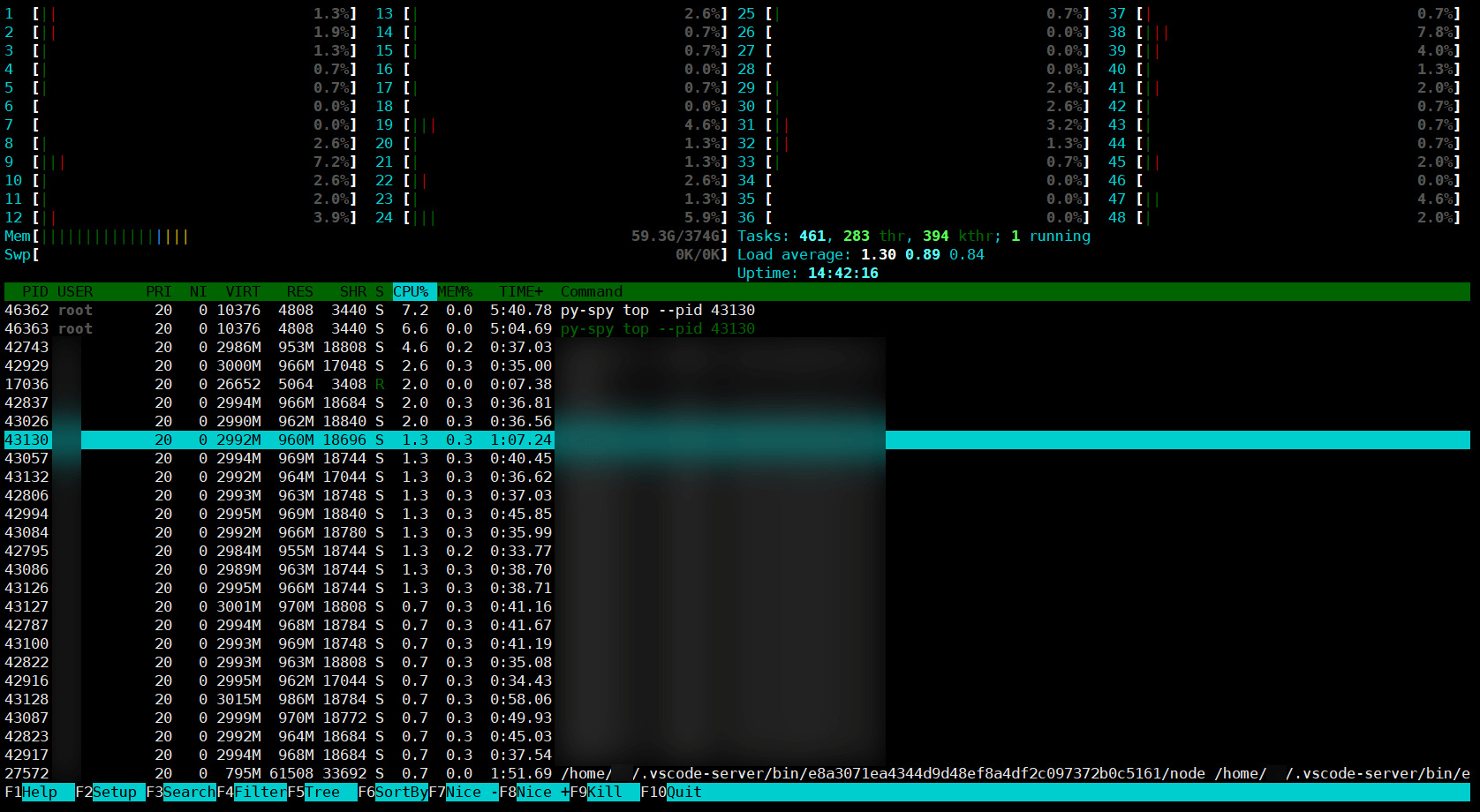 启动后的 client htop。
启动后的 client htop。server 情况:
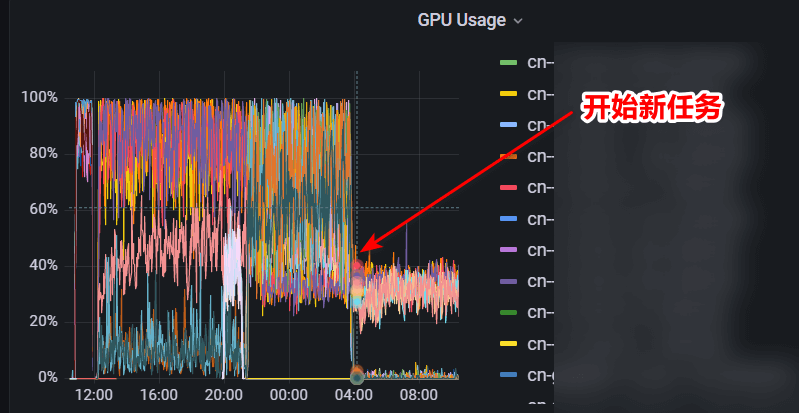 启动后的 server GPU 利用率。
启动后的 server GPU 利用率。server 这边显示的是所有服务器的 GPU 的情况,包括旧任务的,而且此时旧任务还没有完成。但是新任务一开始基本就出现了利用率的下降,请求量也出现了下滑(但是没有利用率那么明显):
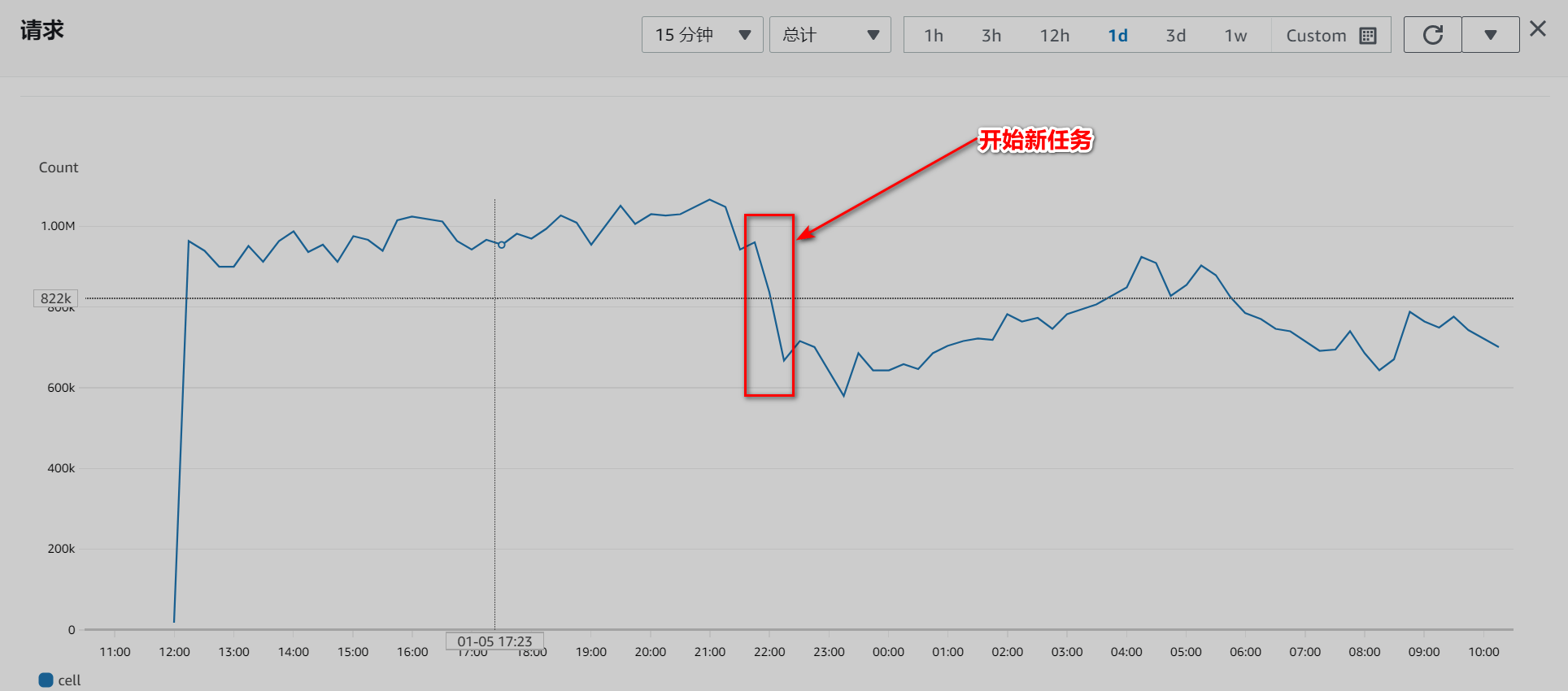 负载请求量。
负载请求量。从日志中可以看到旧任务一些进程已经结束了,但是也不至于出现这么大的波动。这就很奇怪了,为什么新任务一开始 server 那边就打不满了呢,按理说应该更满才对,而且请求量也没上去,反而跌了。
我先是用 py-spy 检查了其中一个进程到底在干什么,这个工具的一个重要功能就是可以检查处于运行状态下的进程在干什么。结果如下:
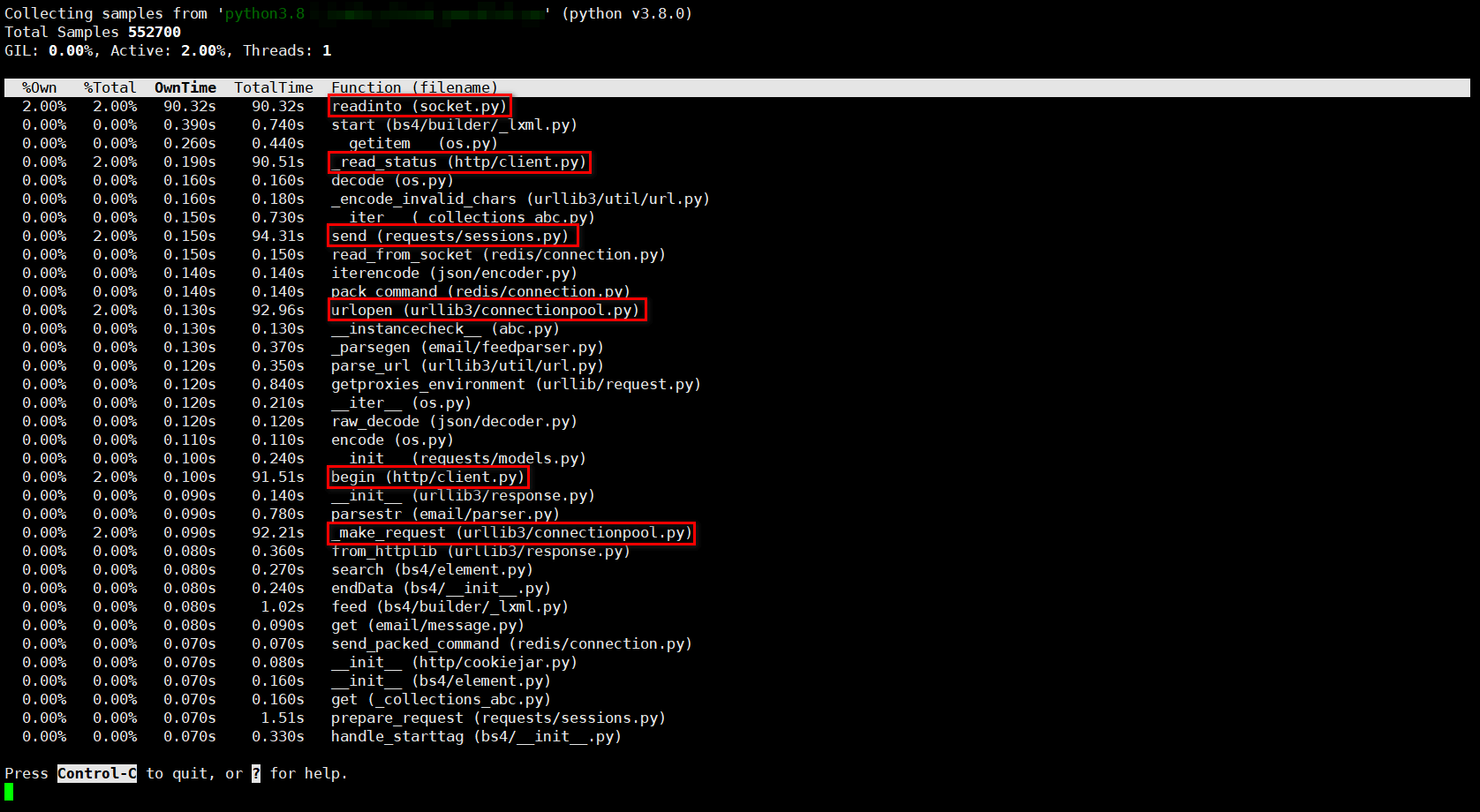 py-spy 结果。
py-spy 结果。可以看到,时间基本都消耗在了网络相关函数上,比如 readinto (sockent.py) 、send (requests/sessions.py) 、urlopen (urllib3/connectionpool.py) 、begin (http/client.py) 和 _make_request (urllib3/connectionpool.py) 。很明显,问题出在网络上。正常情况 BeautifulSoup 相关操作应该占比较大一部分。
运维测试了下网络,延迟很低,网络很通畅……
然后我在监控中看到 server 镜像版本是旧的,而且这个旧镜像是有问题的,根本启动不起来。从监控中也可以看到这几台 server 利用率一直是 0,也就是说根本没收到请求。如果 server 没起来,那么负载应该是不能连接的,但我在 client 这边并没看到负载连接失败的报错,而且我在 client 程序最前面加了一个负载连接测试,不通过会直接 raise error,程序就会退出,而现在程序是正常运行的。这是为什么呢?还记得前面说过这个负载是和旧任务共用的吗,问题就在这里,这里实际上用的还是旧任务的 server,所以不会出现连接错误。
把这个问题解决了后,问题依旧,server GPU 利用率稍微降低了些,但波动很小:
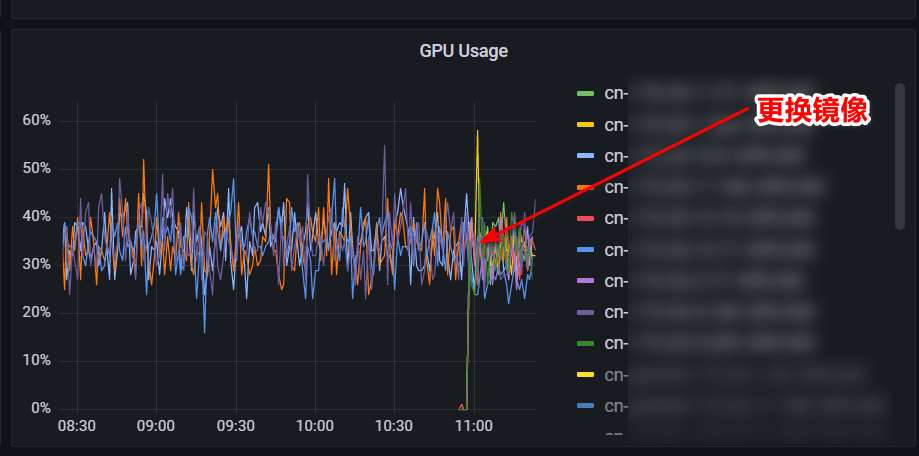 解决 server 镜像问题后的 GPU 利用率。
解决 server 镜像问题后的 GPU 利用率。尽管大家觉得还是很离奇,但是当时时间很晚了,大家建议尝试增加 client 这边的并行核数(joblib 的 n_cores),毕竟 client 这边不满 server 也不满的另一个可能的原因是并发不够,同时打出去的请求不够多。
后来的小时测试发现速度增加了 5 万/小时,但是不知道这是谁的功劳,或者说这个速度是不是存在水分都不一定,因为我不是特别确定之前的速度。由于时间很晚了,这件事暂且告一段落了。
后来同事向我反馈线上 api 总是超时,之前不会。我进去看了下日志发现是有个子任务超时了,进一步发现 dev 服务器上的 GPU 特别满,按理说应该不可能,请求的人没那么多。这时我突然想到,为了方便在负载地址和 dev 地址之间切换,我在配置文件里区分了 prd 和 dev,批处理数据时需要先用如下语句来初始化配置:
1 | config = Config('prd') # or 'dev' |
这个语句在两个程序中会出现,我突然想到我在其中一个程序中似乎还是用的 dev ,有可能会导致批处理用了 dev 服务器上的模型服务。进去一看,果然!
这就解释了为什么 client 和 server 都很闲:
- client 很闲是因为 dev 服务器忙不过来,瓶颈在 GPU 这边,即使增加 client 核数也没用;
- server 也不忙是因为一部分请求根本没发到负载。
但是为什么 server GPU 利用率下降了那么多,只能用旧任务一些进程结束来解释了,当然负载可能也存在问题(后来决定按照任务来生成不同的负载地址,做一下隔离,能避免如服务器没起来但负载仍可以连接的情况,也可以更好地看到不同任务地情况)。
改成 prd 后 client 这边 CPU 正常了:
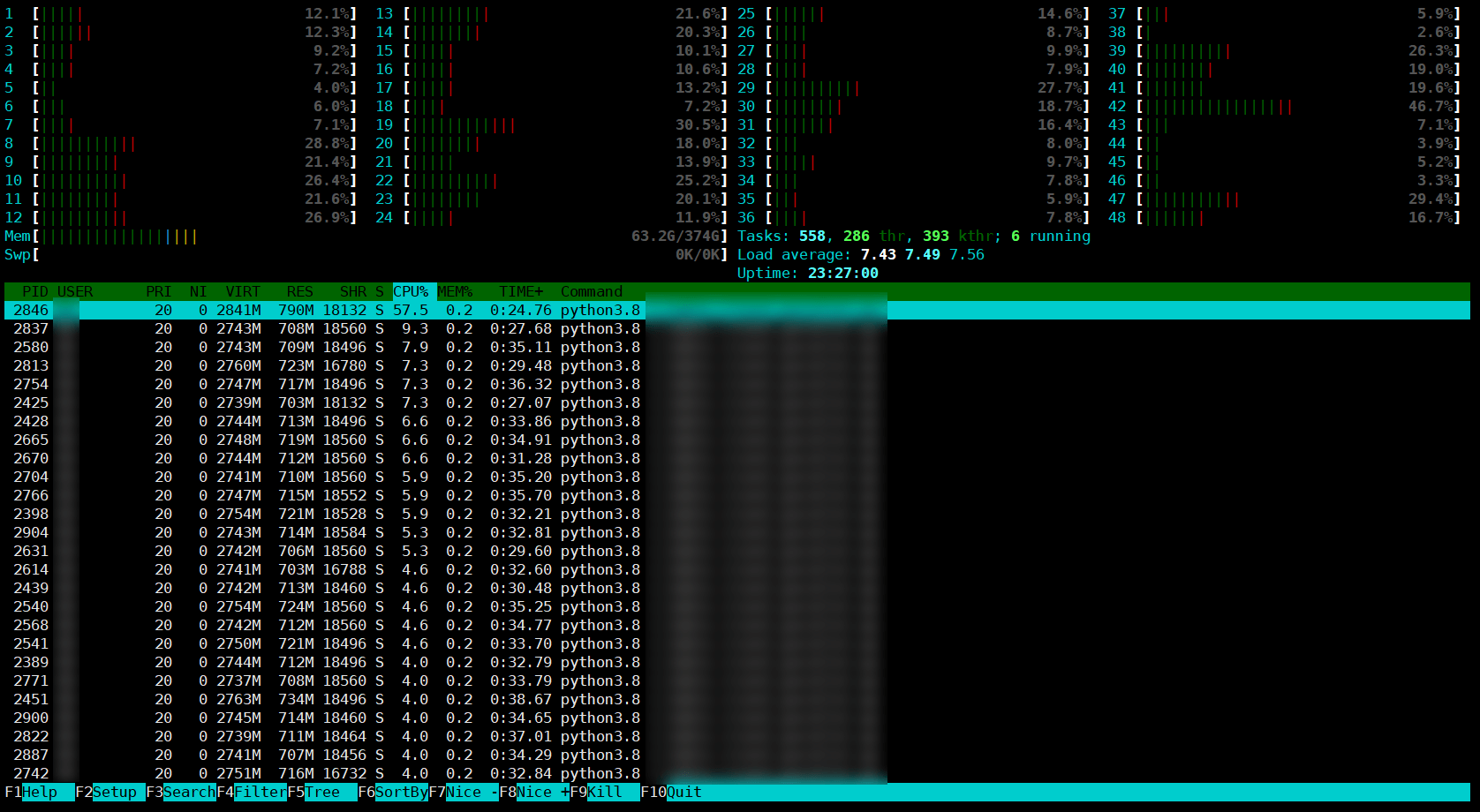 修正后的 client htop 结果。
修正后的 client htop 结果。总结
经过这件事,意识到几点:
- 特别注意配置文件中的配置项是否正确。
- 配置尽量初始化一次,然后全局使用。
- Profiling 工具很重要,尤其是能 profile running program 的。
- 尝试了很多种方法后仍然不能解决问题,卡住了,先放一放。
- Be patient。