
关于 C4 数据集
参考 Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus。
- 从 365 百万 domain 中抓取,共计大约 1560 亿 token。
- 用来训练 T5 和 Switch Transformer。
- Raffel et al. (2020) 提供了重新创建 C4 的脚本,但是运行这些脚本大概需要数千刀。
- C4 是以 Common Crawl 2019 年 4 月的 snapshot 为基础创建的,使用了很多 filter 来过滤文本。
- 这些 filter 的作用包括:
- 删除没有 terminal punctuation mark 的行。
- 删除少于 3 个词的行。
- 删除少于 5 个句子的文档。
- 删除包含包含 Lorem ipsum 这种 placeholder 文本的文档。
- 删除包含“List of Dirty, Naughty, Obscene, or Otherwise Bad Words”中任何单词的文档。
- 删除非英文文档,非英文的标准是使用
langdetect得到的英文概率小于 0.99,所以 C4 主要是英文文档。
- 应用了 filter 的数据集版本叫 C4.EN,没应用的叫 C4.EN.NOCLEAN,没有使用 blcoklist 的 C4.EN 叫 C4.EN.NOBLOCKLIST。三个版本的简单统计如下图,其中 token 数是用 spacy 的 English tokenizer 分词后统计的:
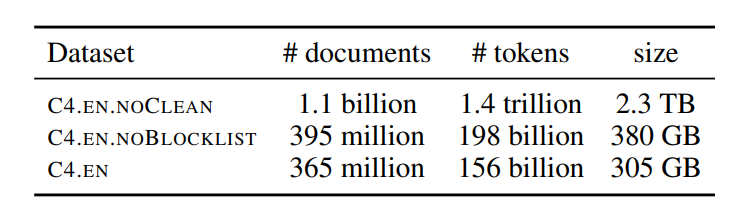 三个版本的 C4.EN 统计
三个版本的 C4.EN 统计 - 来源网址中,按 TLD(top-level domains)统计,前三名是 .com、.org、.co.uk,其中 .gov 和 .mil 占比也不少,后者尽管不在 top25 中,但是也有 33 百万 token。
- 按网站统计,前三名是
patents.google.com、en.wikipedia.com、en.m.wikipedia.com。 - 按发表时间统计,92% 都发表在数据集收集前的一个十年中(2011-2019),分布是长尾分布 long-tailed,大部分都在数据收集前的 10-20 年间。这是从 C4.EN 中采样得来的,采样大小为 1 百万。发表时间是按照该网址被 Internet Archive 首次索引收录的时间算的,所以真实发表时间实际更早一点。
- 按地理位置统计,作者使用了一个 IP-country 数据库,从原始数据集中随机采样了一个大小为 17 万 5 千的样本集。前五名是美国(51.3%)、无法分辨、德国、英国和加拿大。中国排在第 18,香港排在第 16。值得注意的是,按人口算第 2、3、4 大说英语的国家——印度、巴基斯坦、尼日利亚、菲律宾,在数据集中占比只有美国的 3.4%、0.06%、0.03%、0.1%,尽管他们有数千万人说英语。
- C4 包含大量机器生成的文本,machine-generated text,主要包括专利的机器翻译和 ocr 文本。前面说过,按网站统计
patents.google.com排第一,这是专利网站,Google 会使用机器翻译模型翻译非英文专利,也会使用 ocr 将扫描文本识别出来。识别哪些文本是机器生成的也是一个活跃的研究领域。 - C4 中存在 benchmark data contamination 现象,即下游任务的训练集或测试集出现在 C4 中,造成了数据污染。具体来说,分为两种情况:input-and-label contamination 和 input contamination。
- 一些 seq2seq 任务的 label 其实就是 input 中的文本,例如抽取式摘要,如果这种任务的 input 出现在了预训练数据集中,那么其 label 也相当于出现在了预训练数据集中,那么我们有理由认为模型实际上只是在背书而没有做真正的推理。作者分析了 3 个生成式任务的7个数据集,发现均有不同程度(1.87-24.88%)的污染,target 文本为单句的匹配率(完全匹配)要明显高于多句。
- Input contamination 同样会对下游任务造成影响。作者发现有 2-50% 的 GLUE input 出现在 C4 中。对于分类任务来说,虽然不包含 label 的训练集出现在 C4 中并不影响最终性能,但是对 zero-shot 和 few-shot 来说,这仍然是一个值得慎重对待的问题。
- C4 带有明显的种族偏见,“Jewish”更容易与积极情绪挂钩,而“Arab”更容易与消极情绪挂钩。
- 对被排掉的文档进行随机抽样,得到 10 万份文档,然后进行 k-means 聚类,k=50,使用 TF-IDF 进行 embedding,然后使用 PCA 进行降维可视化。但最终发现只有 16 个类,且三分之一的是性相关文档。
- 相比于种族,提及性取向的文档更有可能被排除,例如 lesbian 和 gay。这个结论是通过计算点互信息 PMI 得到的。
- 非裔美国英语 AAE 和西班牙裔美国英语 Hisp 更有可能被排除。
- 许多被排除的文档并不包含 offensive 和 sexual 内容。
- 97.8% 的 C4.EN 是白人英语 WAE,AAE 和 Hisp 分别只有 0.07% 和 0.09%。
- 在创建数据集的过程中,评估 bias 很重要。
- 在清洗 web-crawled 数据时,作者反对使用黑名单的方法来排除文档。
- 作者分析的是 C4.EN,所以本文结论可能并不适合其他语言。
- GPT-3 的作者在训练完成之后,才发现存在 benchmark contamination。由于重新训练非常昂贵,他们没有重新训练,转而分析不同任务受到该现象的影响,发现确实会影响相关 benchmark 的性能。