
UpSet Plot 简易指南(一)
目录
我们都知道在展示几个集合的交集情况时,应该使用维恩图,非常直观。但是当集合数大于 3 的时候,维恩图就很难绘制了,或者说即使绘制出来,可读性也非常差,让人看得云里雾里。
最近 The Illustrated Transformer 的作者 Jay Alammar 发了个推提到了这个问题:
What symptoms do covid patients report?
— Jay Alammar (@JayAlammar) December 24, 2021
Visualized via a ven diagram and by an https://t.co/ba5KTcXKDK plot in Altair https://t.co/SOc8qPyOZ2
The two bar charts provide great slices of the data. pic.twitter.com/fDxUMlJoi6
说的是两幅图的比较。看下面这个展示不同新冠症状报告人数的维恩图。哪个圆圈代表什么,交集代表什么,已经很难看出来了。
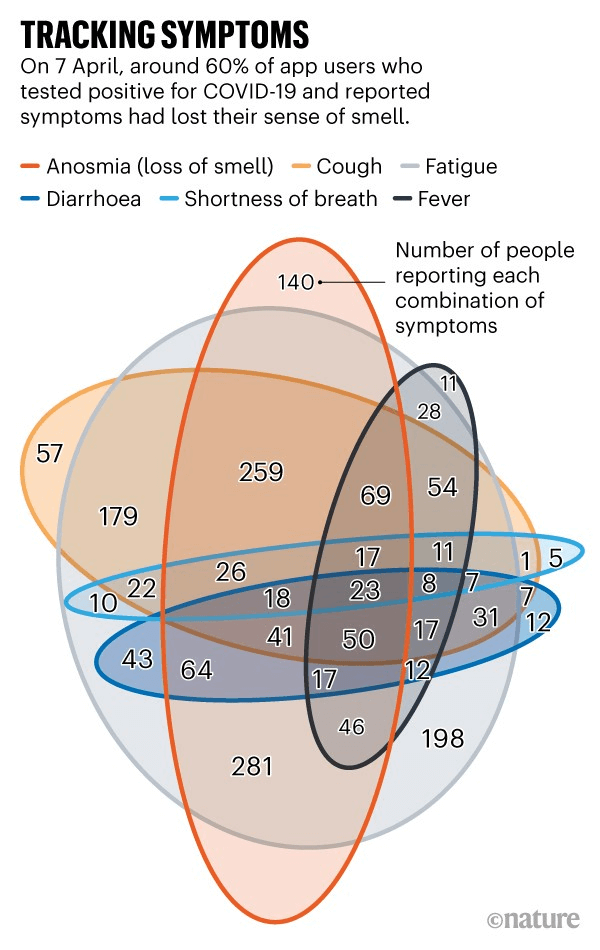 杂乱的维恩图
杂乱的维恩图再看下面这幅图:
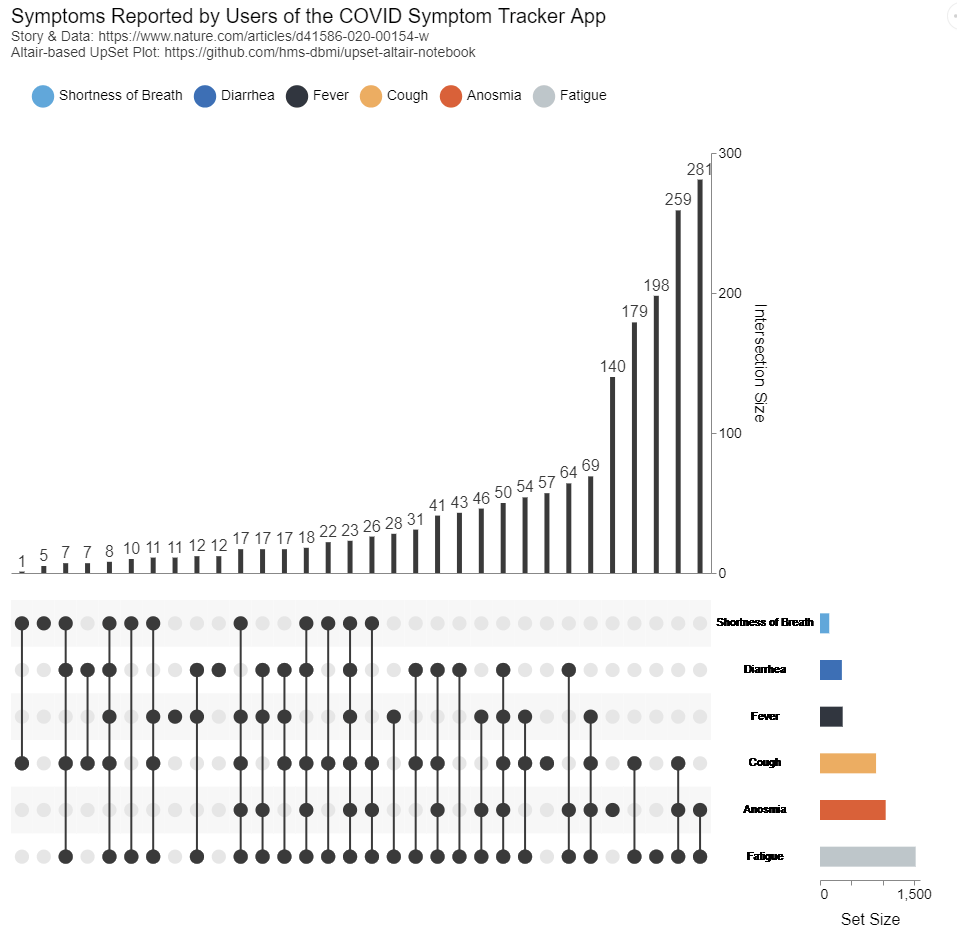 瞬间清晰多了是不是
瞬间清晰多了是不是我们不仅可以很直观地看出来疲劳 Fatigue 的报告人数最多,还可以知道同时报告疲劳和嗅觉丧失 Anosmia 的人最多。
再比如,下面这张出自发表在 Nature 上的《The banana (Musa acuminata) genome and the evolution of monocotyledonous plants》,该图意图是展现香蕉和其他五个物种的基因组之间的交叉重合关系,每个颜色的大圈代表一个物种的基因组:
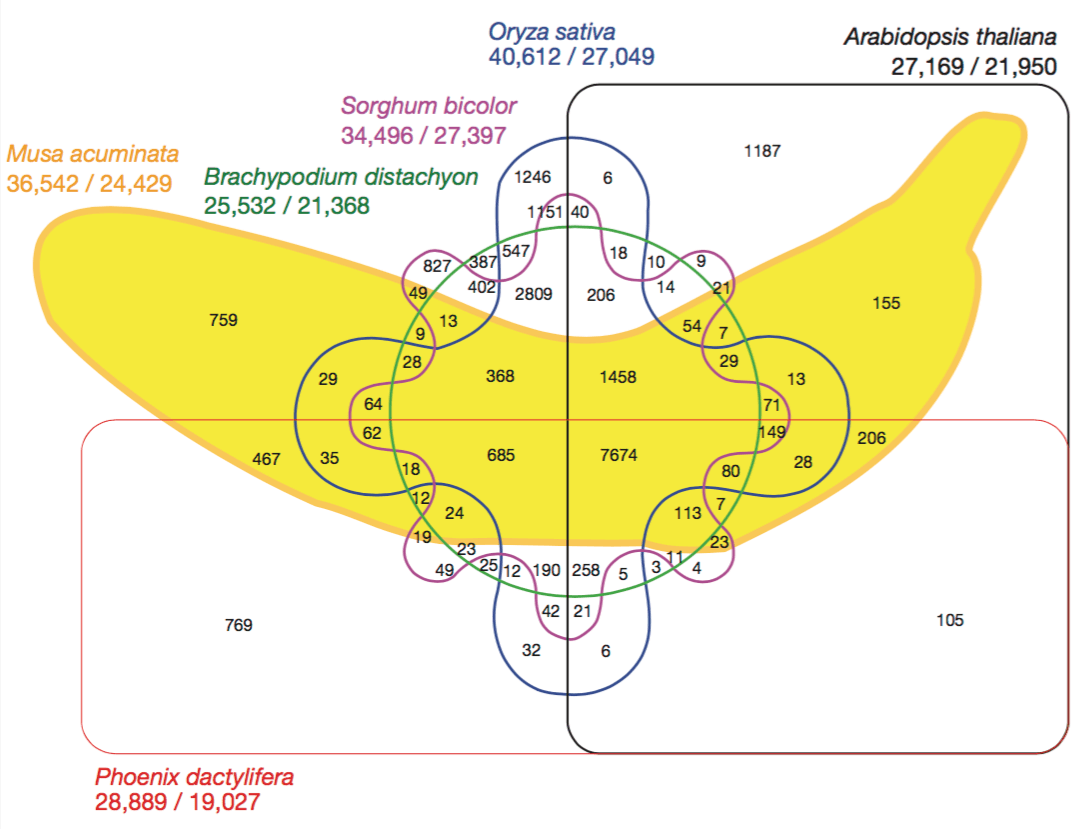 香蕉和其他五个物种的基因组之间的交叉关系
香蕉和其他五个物种的基因组之间的交叉关系一眼看起来还挺好看,但是仔细看你就会发现很容易乱,交叉实在是太多了。那绘制成上面说的那种图会是什么样呢?
 瞬间清晰多了是不是
瞬间清晰多了是不是这样看就舒服多了。很明显可以看出来这六个物种的基因组大部分都是相同的。
这种图就叫 UpSet。我后来具体查了查,发现这种图实在是太有用了,所以决定写一个简易教程,帮助更多人入门。
UpSet 是一种用于可视化多个集合的交叉情况的图形,可以看做是增强的维恩图,专门用来应付这种情况,非常适合集合数多于 3 个时交集情况的展示,由哈佛医学院视觉计算组于 2014 年的论文《UpSet: Visualization of Intersecting Sets》中提出,算是比较新的了。
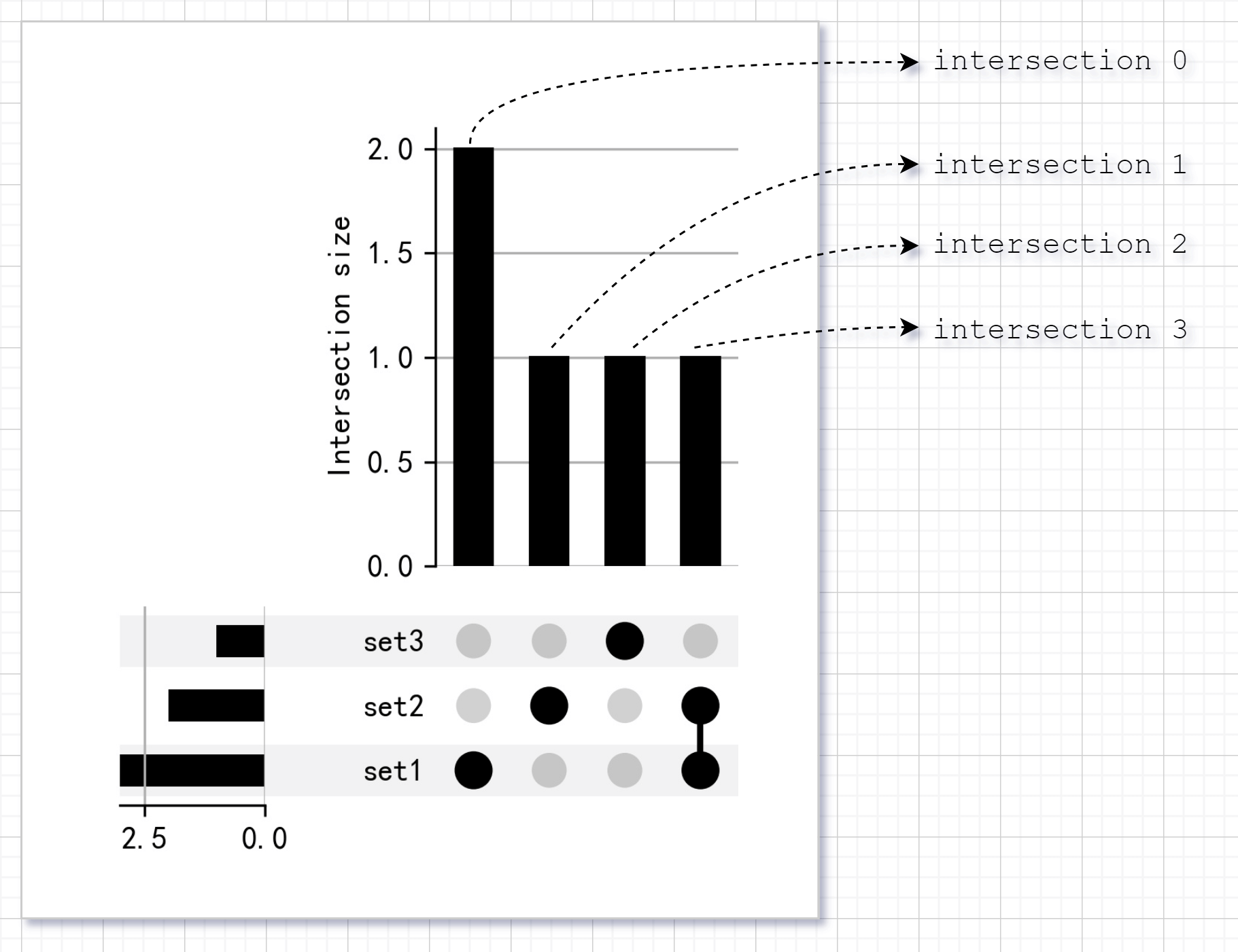
UpSet 由三部分组成,分别解释如下:
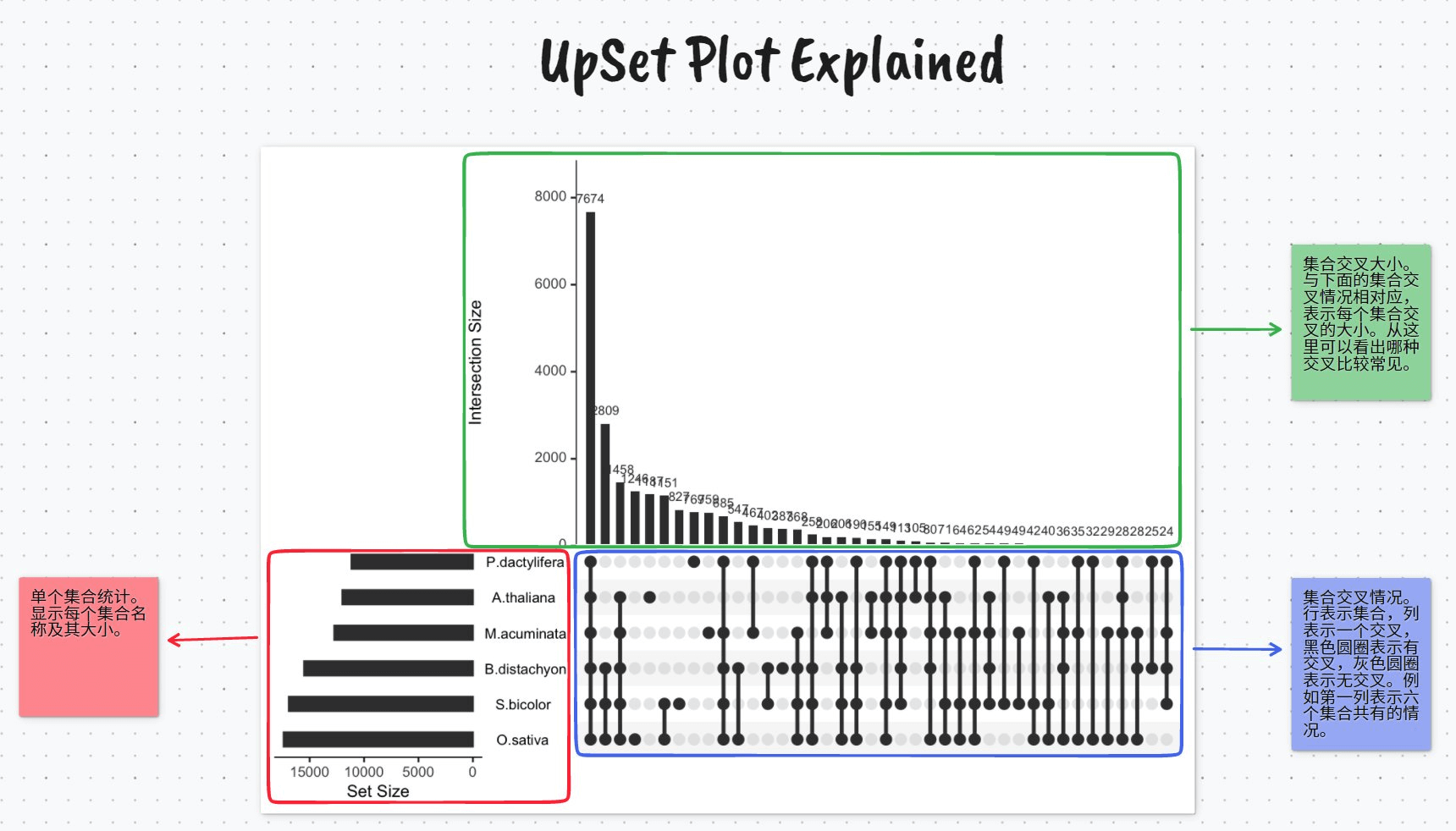 其中蓝色部分也可以看作是绿色部分的 xtick label。底图源自 r-graph-gallery.com。
其中蓝色部分也可以看作是绿色部分的 xtick label。底图源自 r-graph-gallery.com。看起来挺复杂?没关系,你没必要自己 plot it from scratch。upsetplot 是这方面的能手。
和其他 Python 包一样,首先需要使用 pip 安装:
1 | $ pip install upsetplot |
主要方法
upsetplot 的主要 API 是 plot() 方法。主要参数如下:
data:pd.Series或者pd.DataFrame,一般来说是 MultiIndex 的,用来表示 object 的归属情况(归属于哪个集合),其值为 0/1 或者 True/False。这个参数一般是由内置函数生成的,不用自己创建,包括from_contents、from_indicators、from_memberships,可以根据你的源数据的格式选择合适的函数。具体用法下面介绍。fig:plt.figure()对象,可以指定绘制在哪个 figure 上。保存图时有用,如果你不传此参数,直接使用plt.savefig()保存,会得到一个空图。
你也可以传入其他参数,这些参数同时也是 UpSet() 的参数,主要有:
sort_by:subset(即绿色部分)的排序依据,可选的有cardinality、degree(默认值)和None。cardinality表示根据 subset 的大小排序。degree表示 subset 中包含的 set 的数量(即蓝色部分每列黑色圆圈的数量,自由度),会根据这个数量进行排序。set,或者叫 category,就是图中的红色部分。None表示根据数据原本的出现顺序排序。subset_size:如何计算 subset 大小(即绿色部分的柱高),可选的有auto(默认值)、count和sum。auto表示当data是 DataFrame 时,使用count,除非另一个默认为None的参数sum_over被指定为非None。count表示用 group(subset)的行数作为 subset 大小。sum就表示对data进行求和,或者在sum_over指定的列上进行求和。min_subset_size:最小 subset 大小。有时候 subset 过多,需要用此参数来限制 subset 数量。max_subset_size:最大 subset 大小。有时候 subset 过多,需要用此参数来限制 subset 数量。min_degree:最小 degree。有时候不想显示 degree 为 0(即某列中全是灰色圆圈,没有黑色圆圈)或 1 的情况,可以用此参数来限制。max_degree:最大 degree。类上。
基本框架
绘图的基本框架非常简单:
1 | plot( |
kwargs 就是 UpSet() 的其他参数。
准备数据
绘图的核心就是 data 参数,因此如何准备你的数据是至关重要的。
前面我们提到过生成 data 的函数主要有三个:from_contents、from_indicators和from_memberships,下面我们分别来看下传给这三种函数的数据是什么样子的。
from_contents
from_contents 期望的数据格式是一个 dict,key 为 category name(或者叫集合名称),value 为集合中包含的对象列表,这些对象必须是 int 或者 str 格式,即 value 必须是 list of int 或者 list of str。
例如下面这样:
1 | contents = { |
传给 from_contents 后生成的数据如下:
1 | from_contents(contents) # DataFrame |
这返回的数据就是一个 MultiIndex DataFrame,将之传给 plot() 即可绘图,如下图左边:
其等效的维恩图如下:
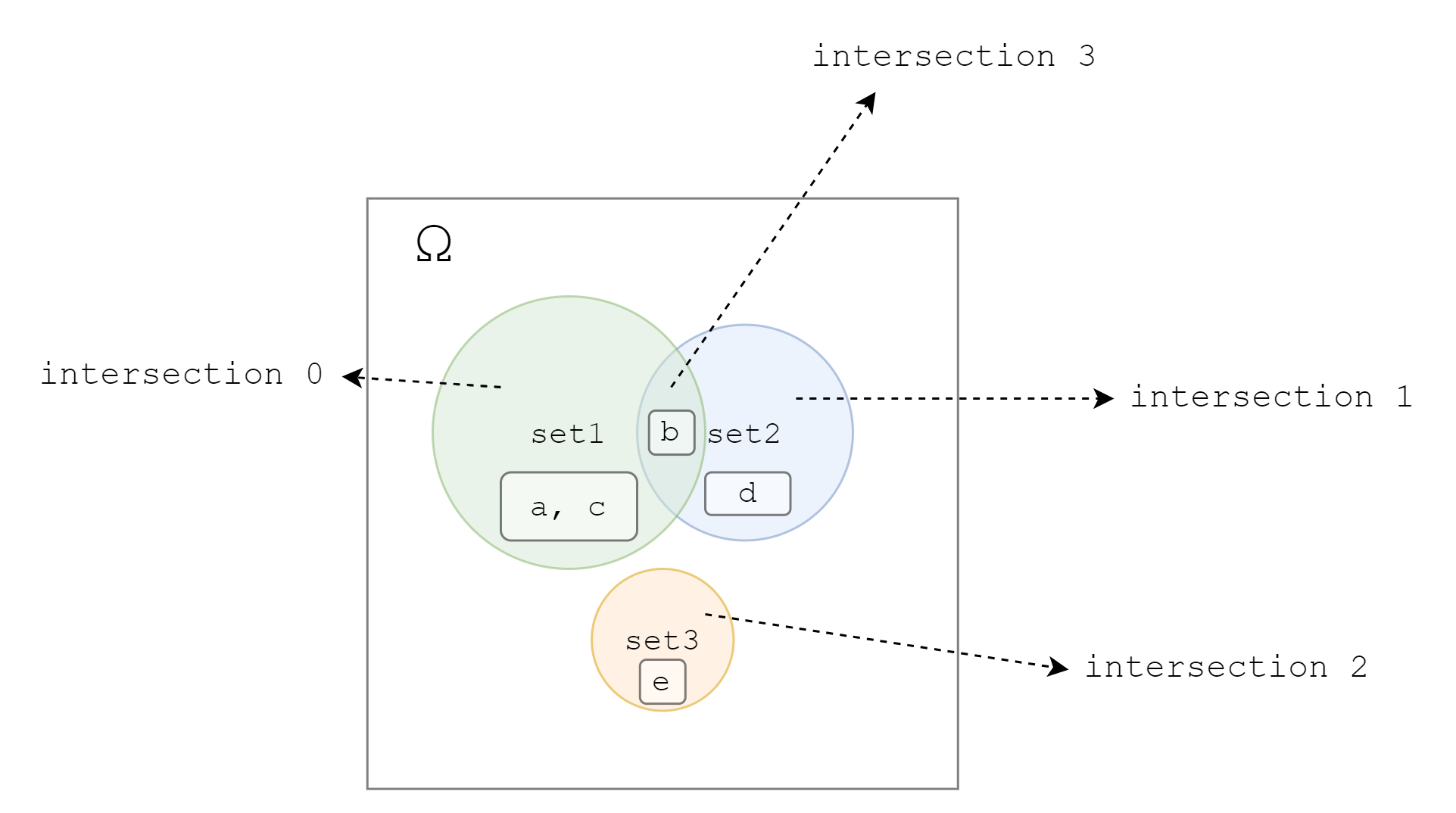 与上图等效的维恩图
与上图等效的维恩图from_indicators
indicator 是“指示符”的意思,类似指示函数 indicator function 返回的是 0 和 1,from_indictors 也期望输入是一个只包含 bool 类型的数据。可以是一个 dict、一个 DataFrame,但总归是一个表格类型数据。列名是集合名称,value 是 True/False,表示某个对象属不属于该集合,所以 value list 的长度或者 DataFrame 的长度就是对象数量。
例如:
1 | # dict 类型的输入 |
结果图同上。
from_memberships
from_memberships 就比较直接了,是一个嵌套 list,每个 item 也是一个 list,表示一个对象的归属情况,里面的每个 item 是 str 类型的集合名称,即每个对象的”会员关系“ memberships,它们都是哪家的会员。
我们还是沿用上面的例子:
1 | memberships = [ |
传给 from_memberships 后生成的数据如下:
1 | from_memberships(memberships) # Series |
最后的结果图和上面一致。
复现
现在我们来尝试复现一下本文开头提到的 Jay Alammar 的推特中的图。
我们这里使用的是最新数据,所以最终结果可能和原图有所不同。
原图中的数据来自 https://ndownloader.figshare.com/files/22339791,我们可以直接使用 pd.read_csv() 来读取,
1 | df = pd.read_csv("https://ndownloader.figshare.com/files/22339791") |
我们可以看到输出的 dataframe 非常符合 from_indicators() 的情况,所以我们用之来绘制 UpSet。但是在这之前,我们需要先删掉 id 列并把数据类型转成 bool :
1 | df = df.drop('id', axis=1).astype(bool) |
然后我们就使用 from_indicators() 来绘图了:
1 | plot(from_indicators(df), subset_size='count', sort_by='cardinality') |
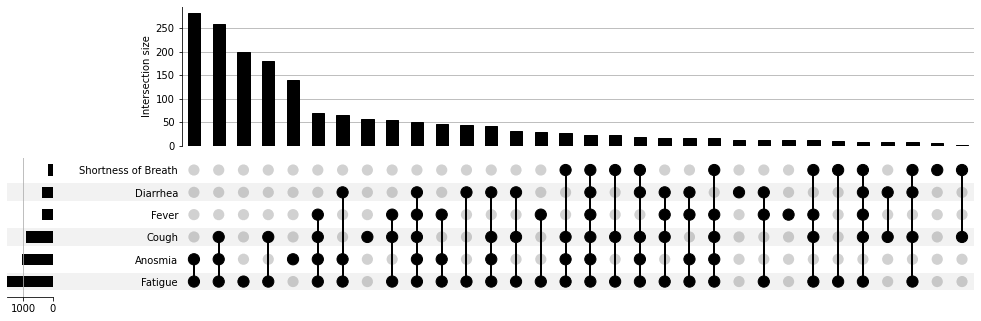 和原图的结论基本相同。
和原图的结论基本相同。和原图的结论基本相同。
下一篇,我们将看到更多的实际例子以及如何解决一个棘手的问题。