
NLP 中的通用数据增强方法及针对 NER 的变种
目录
- 通用数据增强方法
- 针对序列标注的数据增强方法
- 一些可用的库
- Reference
本文结合 A Visual Survey of Data Augmentation in NLP 和最新的综述论文 A Survey of Data Augmentation Approaches for NLP,大致总结了目前 NLP 领域的通用数据增强方法和几种针对如 NER 的序列标注模型进行适配的变种方法,关于后者,重点介绍了基于 mixup 改进的 SeqMix 方法。
此外,本文较长,建议结合右侧目录食用。
通用数据增强方法
每个增强方法最后的有序列表是提出或使用该方法的论文列表。
Lexical Substitution
在不改变语义的情况下,替换句子中的词。
Thesaurus-based substitution
使用近义词随机替换句子中的某一个词。
- 2015: Character-level Convolutional Networks for Text Classification
- Siamese Recurrent Architectures for Learning Sentence Similarity
- EDA: Easy Data Augmentation
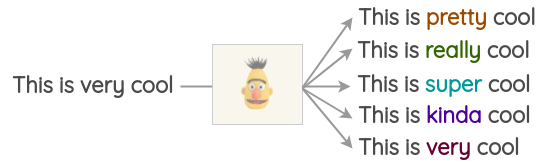
Word-Embeddings Substitution
 Untitled 1.png
Untitled 1.png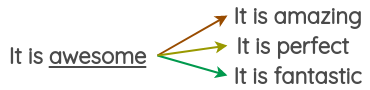 Untitled 2.png
Untitled 2.png- TinyBERT: Distilling BERT for Natural Language Understanding
- That’s So Annoying!!!: A Lexical and Frame-Semantic Embedding Based Data Augmentation Approach to Automatic Categorization of Annoying Behaviors using #petpeeve Tweets
Masked Language Model
BERT、ROBERTA、ALBERT……
 Untitled 3.png
Untitled 3.png有一点需要指出,决定哪个词需要被替换,这是个需要仔细考虑的问题,不然替换后可能会导致语义变化。
 Untitled 4.png
Untitled 4.png- BAE: BERT-based Adversarial Examples for Text Classification
TF-IDF based word replacement
该方法的思想是,TF-IDF 得分较低的词是 uninformative 的,所以对他们进行替换无伤大雅。
 Untitled 5.png
Untitled 5.png- [提出者] 2020: Unsupervised Data Augmentation for Consistency Training
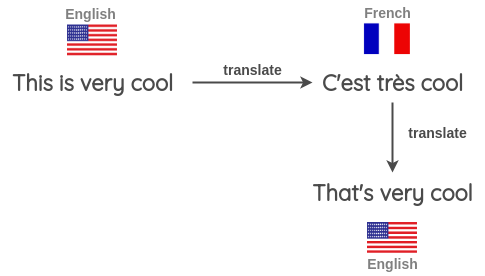
Back Translation
Steps:
- 将句子从一种语言翻译成另一种语言,如英语 → 法语
- 再从法语翻译回英语
- 检查翻译回来的句子和原来的句子是否一样。如果不一样,那就算一个增强样本。
 Untitled 6.png
Untitled 6.png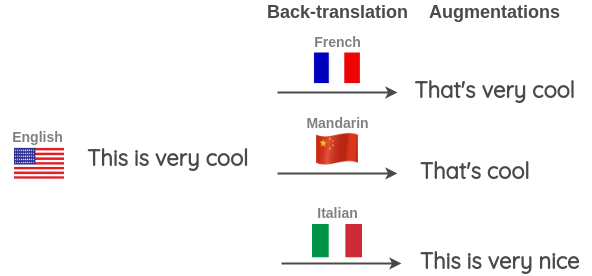 Untitled 7.png
Untitled 7.png可以使用 TextBlob 来实现 BT,你甚至可以使用 Google Sheets:
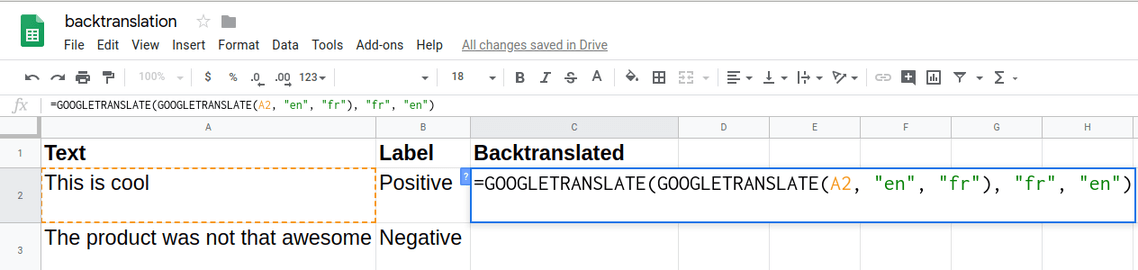 Untitled 8.png
Untitled 8.png- 2020: Unsupervised Data Augmentation for Consistency Training。使用 BT 方法,仅仅使用 20 个标注样本训练的模型,性能超过使用 25000 个标注样本训练的模型,数据集为 IMDB。
Text Surface Transformation
正则模式匹配,例如将动词在缩略形式和展开形式之间来回转换。
 Untitled 9.png
Untitled 9.png但是存在一个问题是,It’s 有可能是 It is 也有可能是 It has:
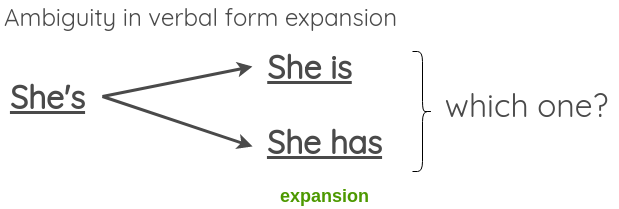 Untitled 10.png
Untitled 10.png为了解决这个问题,作者提出一个解决方法:有歧义的时候就不转,没歧义的时候转。
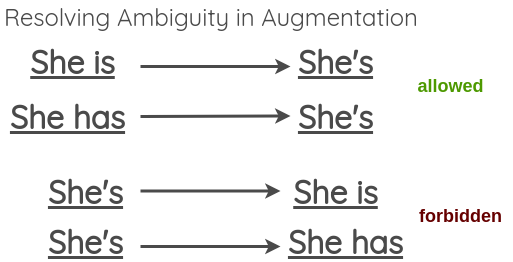 Untitled 11.png
Untitled 11.png- [提出者] 2018: Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs
Random Noise Injection
在文本中插入噪声,这样也可以增强模型鲁棒性。
Spelling error injection
随机拼错句子中的词。
 Untitled 12.png
Untitled 12.pngQWERTY Keyboard Error Injection
模拟人们在键盘输入时因为键位离得近而打错的场景。要用什么字母来替换,基于键盘距离来计算。
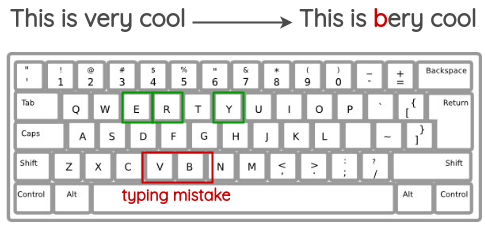 Untitled 13.png
Untitled 13.pngUnigram Noising
根据单词频率分布进行替换。
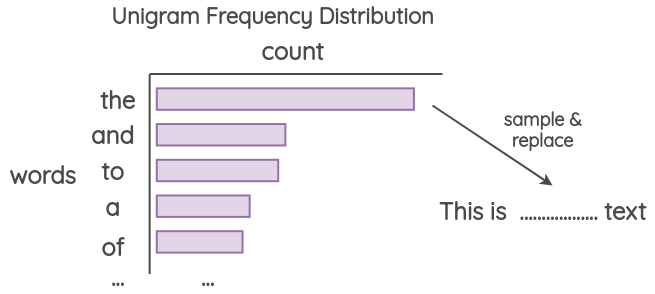 Untitled 14.png
Untitled 14.png- 2020: Unsupervised Data Augmentation for Consistency Training
- 2017: Data Noising as Smoothing in Neural Network Language Models
Blank Noising
使用一个 placeholder 来随即替换一个词。论文中使用 _ 来作为 placeholder,用此方法来避免过拟合和作为语言模型的平滑机制。此方法帮助他们改善困惑度和 BLEU 分数。
 Untitled 15.png
Untitled 15.png- [提出者] 2017: Data Noising as Smoothing in Neural Network Language Models
Sentence Shuffling
随机打乱句子。
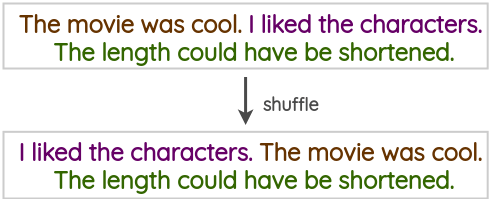 Untitled 16.png
Untitled 16.pngRandom Insertion
Steps:
- 随机选择一个不是 stopword 的词
- 找到这个词的近义词
- 将该近义词插入到句子的一个随机位置
 Untitled 17.png
Untitled 17.png- [提出者] 2019: EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Random Swap
随机替换两个词的顺序。
 Untitled 18.png
Untitled 18.png- [提出者] 2019: EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Random Deletion
根据一定概率删除词。
 Untitled 19.png
Untitled 19.png- [提出者] 2019: EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Instance Crossover Augmentation
由论文 1 提出,灵感来源于遗传学中的染色体交叉互换现象。
Steps:
- 分别将推文 1 和推文 2 拆成两部分
- 将推文 1 的一部分与推文 2 的一部分拼接,组成新的增强推文
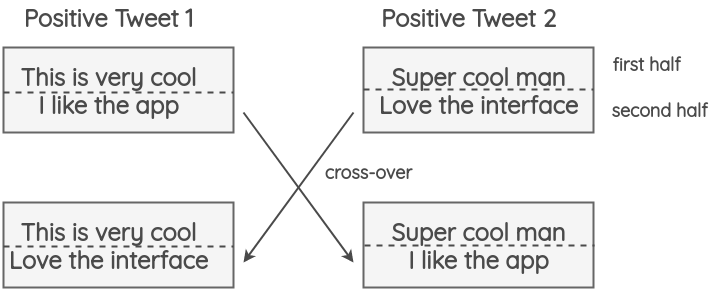 Untitled 20.png
Untitled 20.png论文中发现该方法对准确率没有影响,但是提高了 F1,表明对样本较少的类别还是有好处的。
 Untitled 21.png
Untitled 21.png- [提出者] 2019: Atalaya at TASS 2019: Data Augmentation and Robust Embeddings for Sentiment Analysis
Syntax-tree Manipulation
由论文 1 提出,对句法树依据一定规则进行修改,生成新的增强样本。例如将原先是主动语态的句子,改成被动语态。
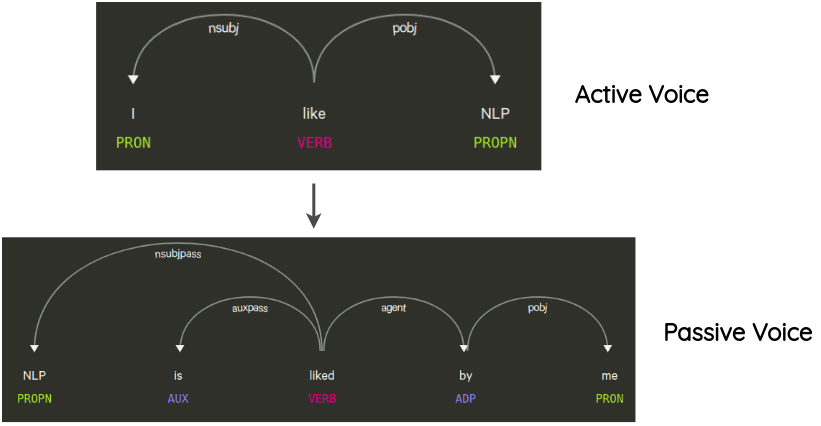 Untitled 22.png
Untitled 22.png- [提出者] 2018: Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs
MixUp for Text
Mixup 原本是用于 CV 领域的增强方法,由论文 1 提出。原本指在一个 batch 中随机选择两张图片,将他们按照一定比例进行叠加。这被认为是一种正则化手段。
 Untitled 23.png
Untitled 23.png后来论文 2 将这个方法适配到 NLP 中,提出了两种适配方法。
wordMixup
和图片叠加是 pixel 相加类似,对于文本,那就是 embedding 相加。随机选择两个句子,将他们的 word embedding 按照一定比例相加,得到一个新的增强样本的 word embedding,作为一个训练样本。最终计算交叉熵损失时,其 ground truth label 就是按相同比例叠加的 label。
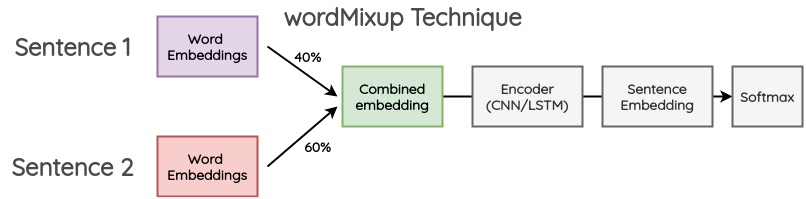 Untitled 24.png
Untitled 24.pngsentMixup
和 wordMixup 不同的是,此方法不是直接将 word embedding 相加,而是通过将原始 word embedding 通过一个 encoder,得到 sentence embedding,再将两个句子的 sentence embedding 按照一定比例相加。计算损失时处理方法同上。
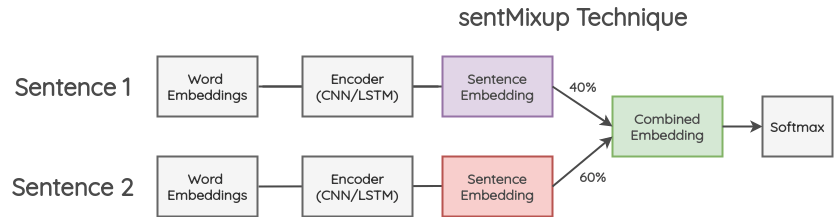 Untitled 25.png
Untitled 25.png- [CV提出者] 2018: mixup: Beyond Empirical Risk Minimization
- [NLP提出者] 2019: Augmenting Data with Mixup for Sentence Classification: An Empirical Study
Generative Methods
在保有原本类别标签的同时,生成新的训练数据。
Conditional Pre-trained Language Models
由论文 1 提出,论文 2 在多个 transformer-based 预训练模型上验证了此方法。
Steps:
在训练集中所有句子前追加其 label。
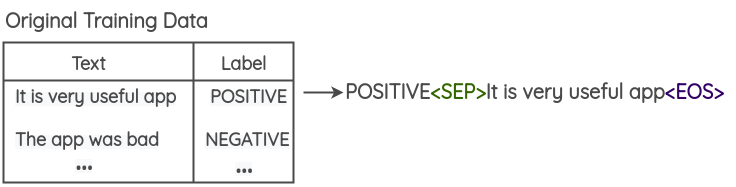 Untitled 26.png
Untitled 26.png使用预训练语言模型在这个新数据集中 finetune。对于 GPT2 来说就是生成任务,对于 BERT 来说就是 masked token prediction。
 Untitled 27.png
Untitled 27.png使用上述训练好的语言模型,根据一定 prompt 生成新的训练样本。
 Untitled 28.png
Untitled 28.png[提出者] 2019: Not Enough Data? Deep Learning to the Rescue!
针对序列标注的数据增强方法
DAGA,EMNLP 2020
GitHub - ntunlp/daga: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Steps:
Linearize。将 token 序列和 label 序列线性化成一个序列。有两种方法:tag-word 和 word-tag。论文发现 tag-word 性能较好,一个可能的原因是 tag-word 更符合 Modifier-Noun 模式,即修饰语-名词模式,这在数据集中非常常见。
 Untitled 29.png
Untitled 29.pngTrain。使用线性化后的数据集训练语言模型。
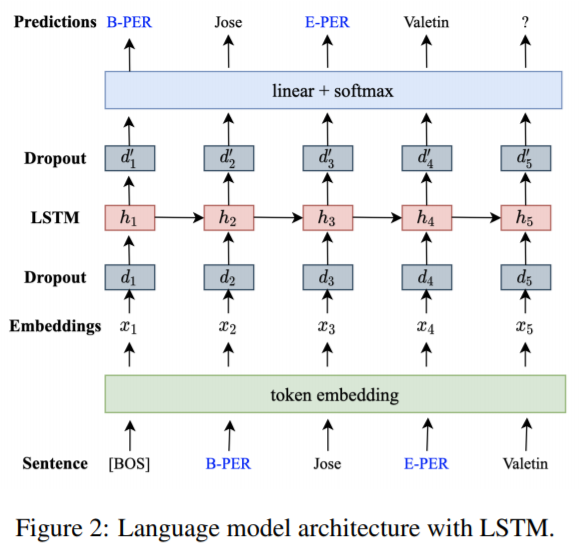 Untitled 30.png
Untitled 30.pngPredict。给定第一个词 [BOS],使用训练好的模型生成新数据。在预测 I have booked a flight to 的下一个词时,由于训练集中有大量 a flight/train/trip to S-LOC 这种模式,所以模型大概率会预测下一个词为 S-LOC。然后再接下来,同样,训练集中 S-LOC 后面接的都是地点如 London、Paris,所以下一个一定是地点词。由于这都是根据概率随机生成的,所以会有比较大的多样性。(感觉是复杂高级版本的实体替换?)
 Untitled 31.png
Untitled 31.png
LwTR,Label-wise token replacement,COLING 2020
Steps:
- 对于每个 token,使用一个二项分布来决定该 token 是否需要被替换。
- 如果是,那么根据从训练集统计得到的 label-wise token distribution,随机选择一个 token 与之替换。
 Untitled 32.png
Untitled 32.png此方法不会导致 label 序列变化。
SR,Synonym replacement,COLING 2020
和 LwTR 相似,只不过不再是从 label-wise token distribution 中选择 token 来替换,而是选择被替换 token 的同义词来替换,该同义词从 WordNet 中获得。
 Untitled 33.png
Untitled 33.png由于某词和其同义词的长度可能不等,所以此方法可能会导致 label 序列变化。
MR,Mention replacement,COLING 2020
这里说的 mention 就是指的实体(应该不包括 O)。该方法本质上就是 SR 的 label-wise 版本。
Steps:
- 对于每个 mention,使用一个二项分布来决定该 mention 是否应该被替换。
- 如果是,从训练集中随机选择一个相同类型的 mention 来与之替换。
 Untitled 34.png
Untitled 34.png和 SR 同样存在长度可能不等的问题,所以也会导致 label 序列变化。
SiS,Shuffle within segments,COLING 2020
这里说的 segment,指的是相同 label 类型的连续序列,一个 segment 仅包含一种实体类型。
Steps:
- 将 token 序列 split 成多个 segment。
- 对于每个 segment,使用一个二项分布来决定该 segment 是否应该被 shuffle。
- 如果是,那么 shuffle。
 Untitled 35.png
Untitled 35.png此方法不会导致 label 序列变化。
SeqMix,EMNLP 2020
该方法实际上也是对 CV 中 mixup 方法的 NLP 适配。
整个方法分成 3 个部分:Pairing、Mixup 和 Scoring/Selecting。
和 CV mixup 同理,此方法中,需要两个句子构成的句子对来进行 mixup。Pairing 就是如何挑选这个句子对的部分。挑选完句子对后,使用一定的 mixup 策略来混合句子对,得到一个或多个增强样本。而这个策略,论文提出了三种不同方法。得到增强样本后,我们需要评估该样本是不是合理,这就用到了 scoring/selecting 部分。该部分会对增强样本进行打分,如果该分值在合理范围内,那么就使用该增强样本。
Pairing
许多序列标注任务中,我们实际感兴趣的 label(即上文说的 mention,论文中称其为 valid labels)是比较少比较稀疏的。例如 NER 任务中,大部分 label 都是 O,我们感兴趣的 PER、LOC 等却比较少。所以,论文设计了一个 pairing 函数,该函数根据 valid label density $\eta$ 来 pairing,定义如下:
其中,$n$ 是 sub-sequence 中 valid label 的数量,$s$ 是 sub-sequence 的长度。
然后设置一个阈值 $\eta_0$,只有当 $\eta \ge \eta_0$ 的时候,才是符合要求的句子。
Mixup
假设 Pairing 后得到序列 1 和序列 2。然后我们有一个 token 表 W,及其响应的 embedding E。
在 wordMixup 和 sentMixup 中,我们是直接将 mixup 后得到的 embedding 作为增强样本的 embedding 送入后续模型,不必得到增强样本的 token 序列。而在此论文中,修改了 mixup 策略,并且还能得到增强样本的 token 序列。
选择 mixed token embedding:
- 与 wordMixup 和 sentMixup 一样,根据比例 $\lambda$ 混合序列 1 和 2 的 token embedding。$\lambda$ 从一个 Beta 分布采样的来。
- 根据 E,计算与混合得到的 embedding 距离最近的 embedding。
- 根据 E、W 和得到的距离最近 embedding,找到该 embedding 对应的 token。
这样就得到了增强样本的 token 序列,label 序列使用同样的比例进行混合。
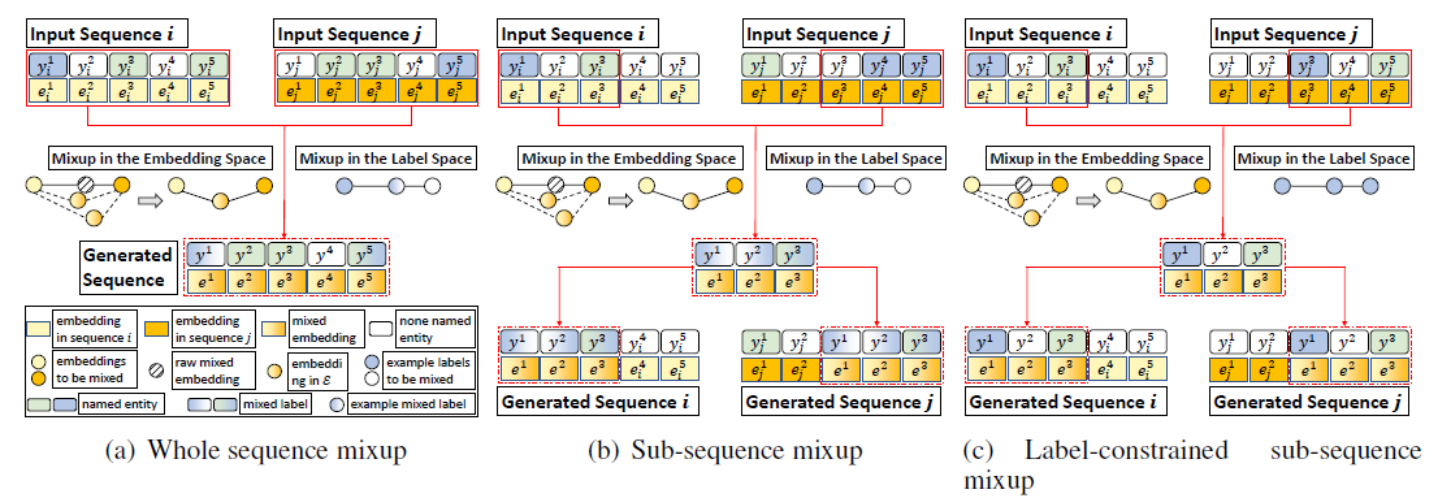
根据 token 范围不同和 label 序列是否混合,有以下几种策略变种:
 Untitled 36.png
Untitled 36.png- Whole sequence mixup:使用整个序列参与混合。
- Sub-sequence mixup:使用序列的一部分参与混合。
- Label-constrained sub-sequence mixup:使用序列的一部分参与混合,且所有 label 保持不变。
Scoring/Selecting
混合比例 $\lambda$ 决定了混合强度,0 或者 1 都表示和原来一样,0.5 则表示一半一半,意味着更强的多样性。但是更强的多样性,也就意味着得到的增强样本有更大风险低质量和强噪声。
所以要通过一个打分函数来控制这个多样性。论文中使用的是 GPT-2 来计算增强样本序列的困惑度。然后判断该困惑度是否在合理区间内。
综合来说,该结合 data augmentation 的 active learning 算法整体过程如下:
 Untitled 37.png
Untitled 37.png其中 SeqMix 部分如下:
 Untitled 38.png
Untitled 38.png作者做了一些实验验证 SeqMix 的性能。数据集使用的是 CoNLL-03、ACE05(14k 标注数据)和 Webpage(385 条标注数据),其中为了验证模型在 low-resource 下的有效性,作者从 CoNLL-03 中随机选择了 700 条数据作为最终训练集,替代原来的 CoNLL-03。而剩下两个数据集,由于标注比较稀疏,保持原样不变。
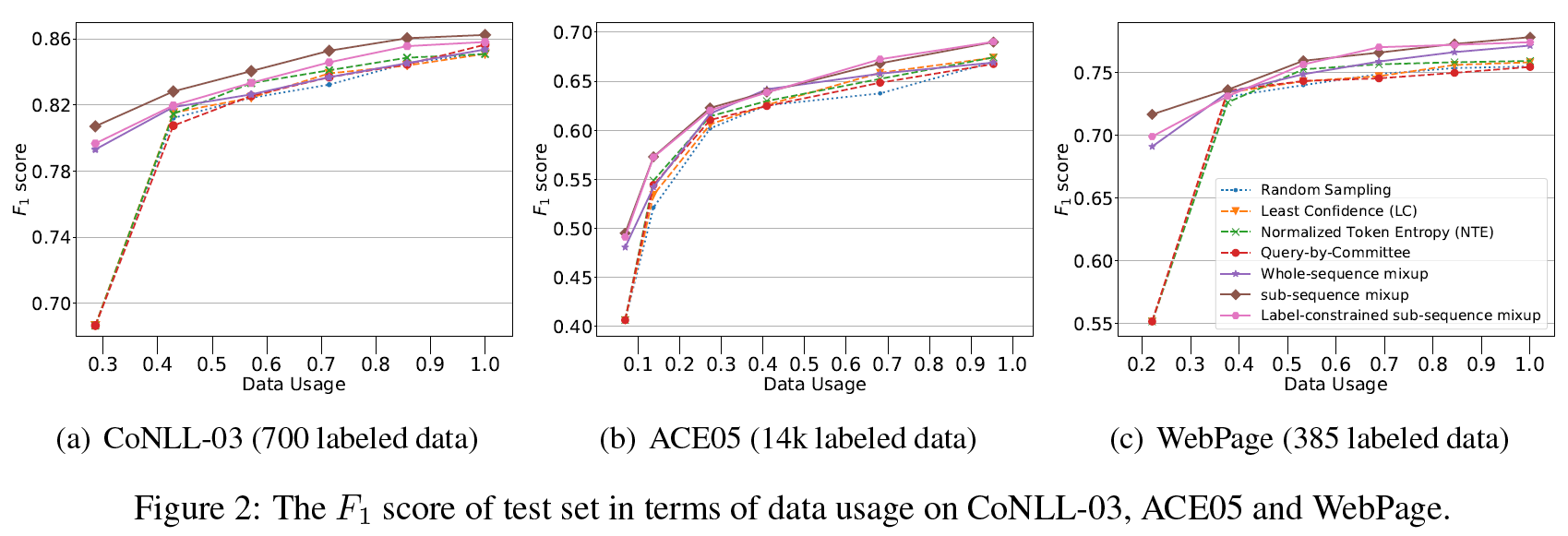
作者按照算法 1 的流程,首先将 SeqMix 与其他 active learning 算法进行对比,SeqMix 部分默认使用 NTE query 策略。结果如图所示:
 Untitled 39.png
Untitled 39.png结果显示:
- SeqMix 方法在所有 data usage、所有数据集上都优于仅使用 AL 的方法。
- 数据越少,SeqMix 效果越明显,与其他 AL 方法的差距越大。
- sub-sequence 方法是三种 mixup 变种中效果最好的,加上 AL 时,使用 NTE 策略效果最好。
随后作者使用 Wilcoxon Signed Rank Test 对该结果进行了统计假设检验。结果显示,whole-sequence mixup 在 ACE05 数据集上没有通过检验,其他方法和其他数据集均通过检验。再结合 Fig 2,可能表明该方法在数据量大时效果不明显或不稳定,这可能是由于该方法在序列较长时可能会生成语义不合理的句子。
而 sub-sequence mixup 方法:
- 保留了 sub-sequence 和原句剩余部分之间的 context 信息。
- 继承了原句的局部信息。
- 引入语言学多样性。
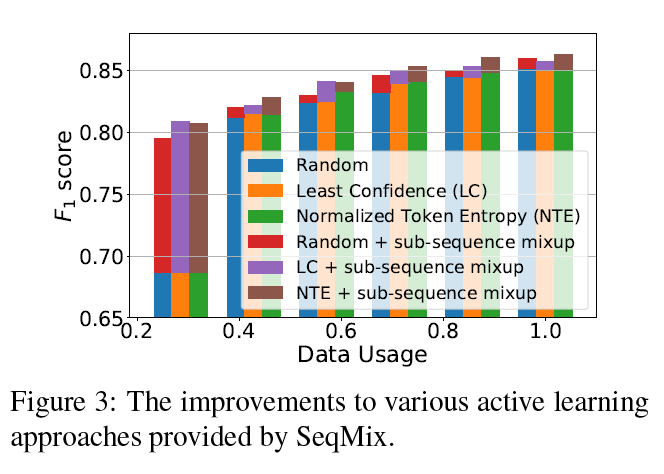
为了验证 SeqMix 方法尤其是 sub-sequence 方法对所有的 AL 方法都有提升,作者进一步将 SeqMix 方法与不同的 AL 方法进行比较,结果如 Fig 3 所示,平均来看,sub-sequence + NTE 的提升最大。
 Untitled 40.png
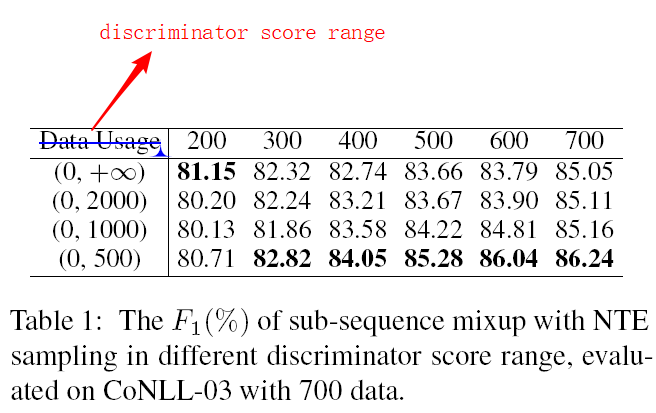
Untitled 40.png此外,作者基于上述实验结果,选用最优组合,即 sub-sequence + NTE,还做了对 discriminator 得分范围、valid label density $\eta_0$、混合比例 $\lambda$ 的分布参数 $\alpha$、augment rate $r$ 的不同参数实验,结论总结如下:
Discriminator 得分范围
 Untitled 41
Untitled 41第一列的表头 Data Usage 应该是错误的,应为 discriminator score range。
使用的数据集为 CoNLL-03,700 个样本。从 200 个样本开始训练,每次 AL 增加 100 个样本,共进行 5 轮。由表可知,得分范围在 $(0,500)$ 时效果最好。
注意得分实际上是困惑度。所以,得分越低,生成的增强样本语义上越好,也就是越顺,也会得到更好的效果。但是也不能无限降低,太苛刻,这样就得不到足够数量的增强样本了。
Valid label density $\eta_0$
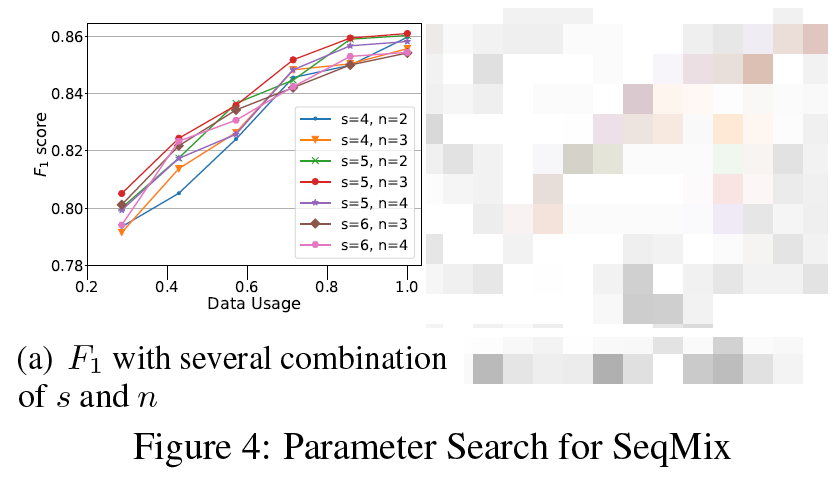
前面说过,VLD 是由 sub-sequence 内的合法标签数 $n$(B-PER 和 I-PER 算两个)和其长度 $s$ 相除得到的。需要注意的是
- 长度 $s$ 的计算。对于 whole-sequence mixup,$s$ 就是整个序列的长度,但是对于 sub-sequence mixup,$s$ 实际上是窗口的大小。
- 实际代码中,是使用合法标签数 $n$ 来选取 valid sub-sequence 的,而不是直接计算比例 $\eta$,所以才会出现下图中 2/4 和 3/6 虽然都是 $\eta = 0.5$ 但是却并存的情况。
 Untitled 42.png
Untitled 42.png由图可知,红色点线代表的 3/5 组合效果最好。
混合比例 $\lambda$ 的分布参数 $\alpha$
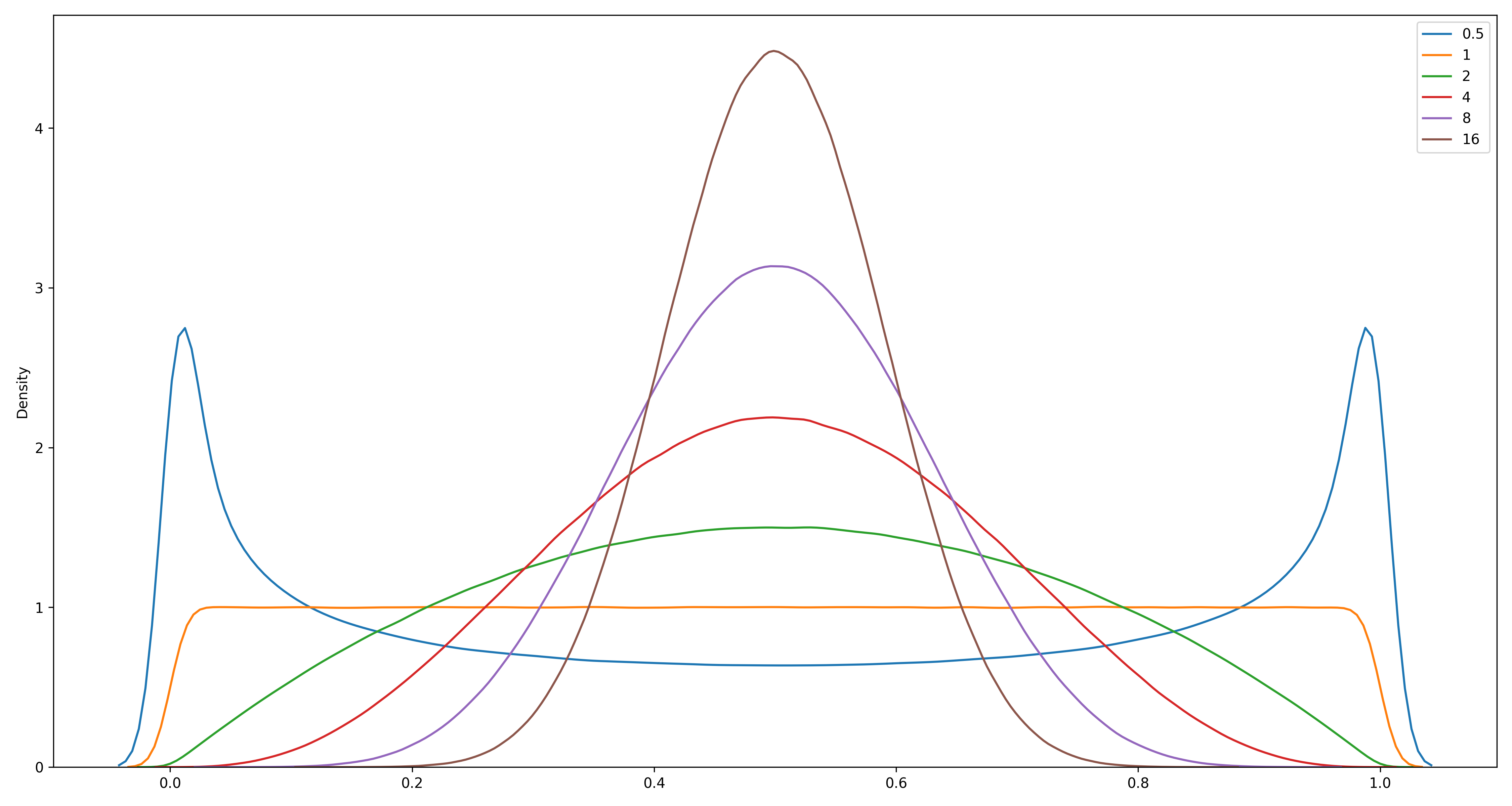
论文中称之为 Mixing parameter。$\alpha$ 是 Beta 分布 的参数,本来 Beta 分布有两个参数,但是此处将两个参数设为相同,即 $\lambda \sim \text{Be}(\alpha, \alpha)$。该分布有个特点,值域为$(0,1)$,参数越大,采样值越有可能在 0.5 附近。
 Untitled 43.png
Untitled 43.png分布参数为 [0.5, 1, 2, 4, 8, 16] 时的分布形状
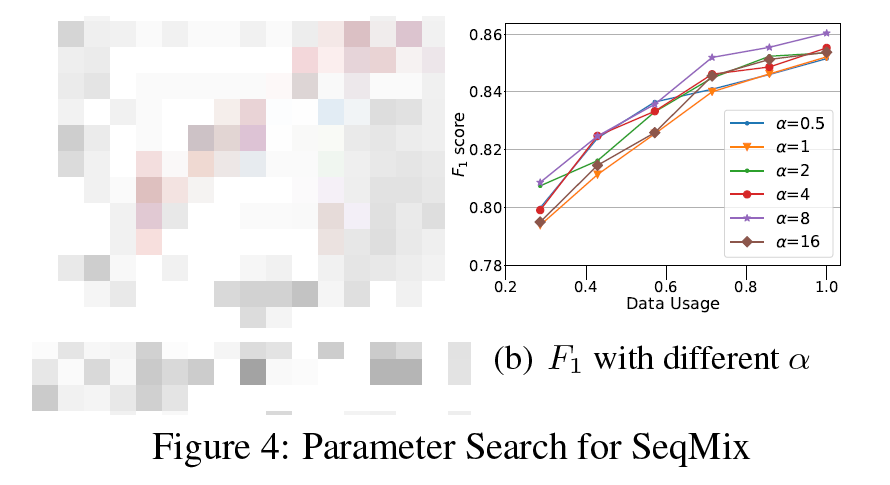
实验结果如 Fig 4(b) 所示:
 Untitled 44.png
Untitled 44.png可见 $\alpha=8$ 时性能最好,此时 $\lambda$ 越有可能在 0.5 附近,意味着为增强样本引入了更多的多样性。但是 $\alpha$ 也不是越大越好,越大意味着 $\lambda$ 的多样性就会减少,进入导致增强样本多样性减少。
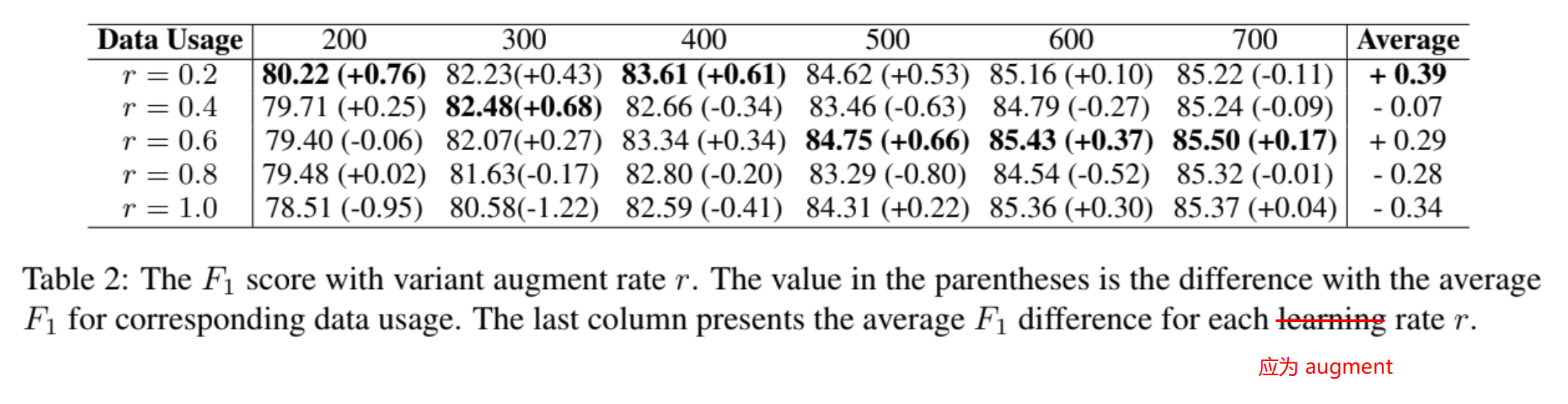
Augment rate $r$
$r$ 的定义如下:
即增强样本数量与原样本数量 $\mathcal K$ 的比例。分母表示使用策略函数 $\gamma$ ,从 unlabelled dataset $\mathcal U$ 中选出 Top $\mathcal K$ 个样本。值域为 $[0, 1]$,所以按照论文中说法,每次最多增强 $\mathcal K$ 个样本。那么每次增强多少呢?实验比较结果如下:
 Untitled 45.png
Untitled 45.png这论文写的也太不严谨了,发现好几处错误了
可见平均来说,0.2 的 augment rate 更为合适一点,说明模型更偏向“温和”一点的增强。总体来说,不宜超过 0.6。
此外我个人觉得,数据量较少时,可能使用较小的 augment rate 好一点;而数据量较大时,可能偏向较大的 augment rate。
一些可用的库
- GitHub - makcedward/nlpaug: Data augmentation for NLP
- GitHub - QData/TextAttack: TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP https://textattack.readthedocs.io/en/latest/
- GitHub - sloria/TextBlob: Simple, Pythonic, text processing—Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more.
Reference
主要参考的是前 3 个,后面几个是找到的但还没来得及看的。
- A Visual Survey of Data Augmentation in NLP
- [2105.03075] A Survey of Data Augmentation Approaches for NLP
- SeqMix: Augmenting Active Sequence Labeling via Sequence Mixup - ACL Anthology
- [1903.09460v1] Data Augmentation via Dependency Tree Morphing for Low-Resource Languages
- [2105.07464v6] Few-NERD: A Few-Shot Named Entity Recognition Dataset
- tata1661/FSL-Mate: FSL-Mate: A collection of resources for few-shot learning (FSL).
- Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning - ACL Anthology