
Constituency Parsing with a Self-Attensive Encoder 论文解读
目录
之前没咋涉略过 parsing 部分,最近有用到,遇到一个实现的很不错的库:benepar,无论是速度、代码还是性能上,伯克利出品。而本文要讲的论文就是 benepar 的参考论文:Constituency Parsing with a Self-Attensive Encoder,代码和论文作者都是一个人:Nikita Kitaev,论文发表于 ACL 2018。代码还参考了作者的另一篇论文:Multilingual Constituency Parsing with Self-Attention and Pre-Training。
看时间,有空了再解读下 benepar 的源代码。写好了我会把链接放在这。
模型总体架构
模型是 encoder-decoder 架构,总体就是两部分:第一部分是给句子中的每一个位置 $t$ 生成一个含有上下文信息的向量表示 $y_t$,即 encoder,这部分借鉴了 Vaswani et al. (2017)1;第二部分是根据 $y_t$ 生成 span 得分 $s(i, j, l)$,即 decoder,这部分主要借鉴了 Stern et al. (2017a)2,参考 Gaddy et al. (2018)3 进行了部分修改。模型总体架构图如下图所示:
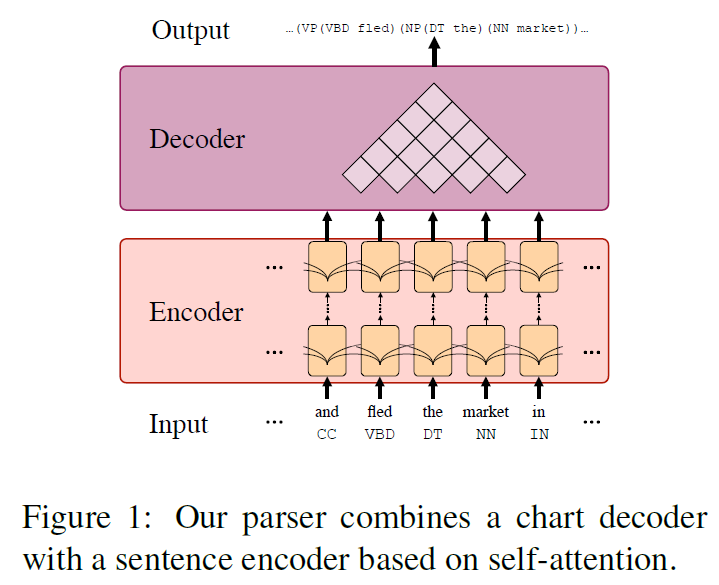 模型架构图
模型架构图Base model
每个实验都会有一个 baseline。作者进行了很多实验,每个实验基本上就是 encoder 部分不同,这也是这个论文的重点,decoder 部分不重要,是一个 chart parser,为每一棵树都计算一个得分,并用一个类似 CKY 的算法找到最佳树。公式如下:
其中:
$\overrightarrow{y}_{k}$ 和 $\overleftarrow{y}_{k}$在 Stern et al. (2017a)2 中分别用的是 BiLSTM 中的正向和反向输出,而本篇论文中是直接将 $y_k$ 分成两半。更多信息可参考 Gaddy et al. (2018)3。
Encoder
encoder 的输入是 word embedding($[w_1,\cdots,w_T]$)、postag embedding($[m_1,\cdots,m_T]$),也存储了一个 learned position embedding($[p_1,\cdots,p_T]$)。这三个矩阵维度相同,最后会把他们加起来:$z_t = w_t + m_t + p_t$。
然后这个 $z_t$ 就会输入一个 stacked 8 层相同的网络,和 bert 那套一样,multi-headed attention、layernorm 等。最后的输出就是 $y_t$。
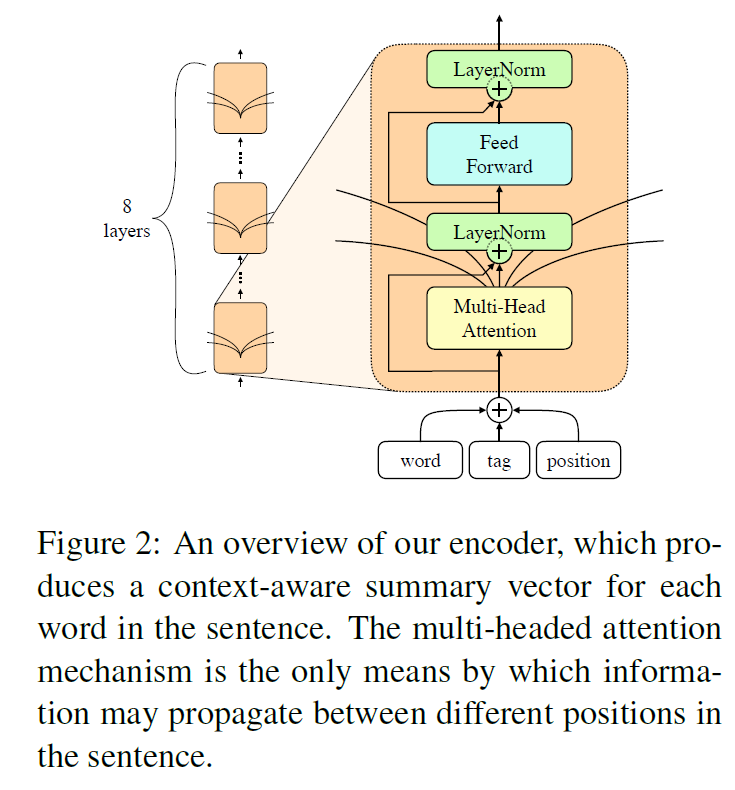 encoder架构图
encoder架构图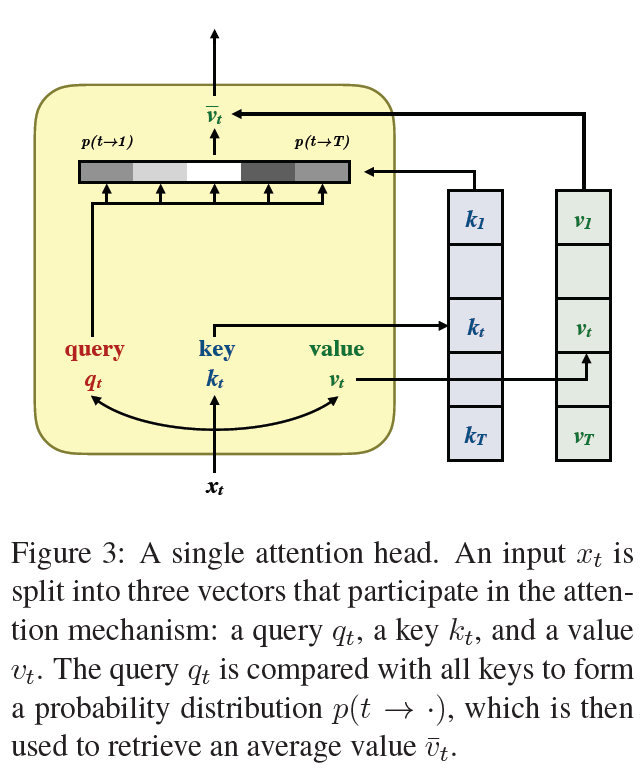 attention head
attention head这个模型最终在 PTB WSJ dev 数据集上的 F1 是 92.67,记住这个数字,以后的模型效果都将会跟这个数字比。
如果将 encoder 换成 LSTM-based,那么 F1 是 92.24,比前者稍低。这也说明了要想取得好结果, RNN-based encoder 并不是必须的,而且 self-attention 还能达到更好的效果。
Factored model
内容特征和位置特征谁更重要?
在 base model 种,信息在 encoder 中传输主要依靠的是 self-attention,可以同时使用内容特征($w_t+p_t$,即 word embedding + postag embedding)和位置信息去获得词之间的相互影响。按道理说,网络可以学习到如何平衡不同的特征信息,但是实践证明不能。所以我们会将会显式地分解模型,拆分内容和位置特征,来提高模型的准确率。
在此之前,为了测量两种特征的重要性,作者做了个测试:禁用内容特征。
HOW?
在每一个 head 计算 $Q$ 和 $K$ 的时候,仅乘上位置信息 $P$,之前乘的是 $X$,即内容 + 位置。而计算 $V$ 的时候仍然使用 $X$。
结果 F1 就降了 0.27,比 LSTM-based 模型还要好。准确率降低在作者的意料之中,但是降了这么少是在意料之外的,作者表示内容特征在模型里占的比重这么小很 strange:
It seems strange that content-based attention benefits our model to such a small degree.
从输入上拆分
下一步,作者猜想两种信息混合(即相加)有可能会让其中一种信息占据主导地位,压制对方,从而影响网络在两者中间找到平衡的最优点。所以作者提出了一个模型的分解版本:显式地拆分内容和位置特征。
HOW?
原来的输入 $z_t = w_t + m_t + p_t$,现在编程 $z_t = [w_t+m_t ; p_t]$,即改成拼接的方式。但是为了保持住输入 $z_t$ 的 size,所以 $w_t + m_t$ 和 $p_t$ 的 size 都会减半。然而实践证明,简单地这样拆分,结果并不好,dev 上的 F1 仅有 92.60,而之前是 92.67。
问题在哪?
首先信息混合的问题根源肯定不在 addition,即 $z_t = w_t + m_t + p_t$。事实上,adding 和 concatenation 在高维度上的表现是差不多的,尤其是当结果会立马乘上一个矩阵之后。关于这一点,我们可以检查这个结果在网络中是怎么被使用的,尤其是注意力中的 query-key 的点乘部分。对于点乘 $q \cdot k$,假如我们把 q 分解成内容和位置特征:$q=q^{(c)}+q^{(p)}$,对 $k$ 同样。然后 $q \cdot k=\left(q^{(c)}+q^{(p)}\right) \cdot\left(k^{(c)}+k^{(p)}\right)$。
然后这里会产生交叉项,比如 $q^{(c)} \cdot k^{(p)}$,这个可能存在隐患,例如这可能会导致得到这样一个网络:单词 the 总是会特别注意句子的第 5 个位置。这种交叉注意力似乎并没有太大作用,反而会带来过拟合。
从注意力层面拆分
作者为了完善这种分解式模型,又使用了一种新的分解方式。对于一个向量 $x=\left[x^{(c)} ; x^{(p)}\right]$,原来是直接乘上权重矩阵 $W$,即 $c = Wx$。
但现在让 $W$ 也跟着拆分,就变成 $c=\left[c^{(c)} ; c^{(p)}\right]=\left[W^{(c)} x^{(c)} ; W^{(p)} x^{(p)}\right]$。模型的很多中间变量都需要跟着改变,包括所有的 query 和 key。然后 query-key 点乘就变成 $q \cdot k=q^{(c)} \cdot k^{(c)}+q^{(p)} \cdot k^{(p)}$。对于一个 attention head 来说,拆分后的情况如图所示,可以看成分别对 $x^{(c)}$ 和 $x^{(p)}$ 应用注意力,后续的 feed-forward 层也同样拆分。
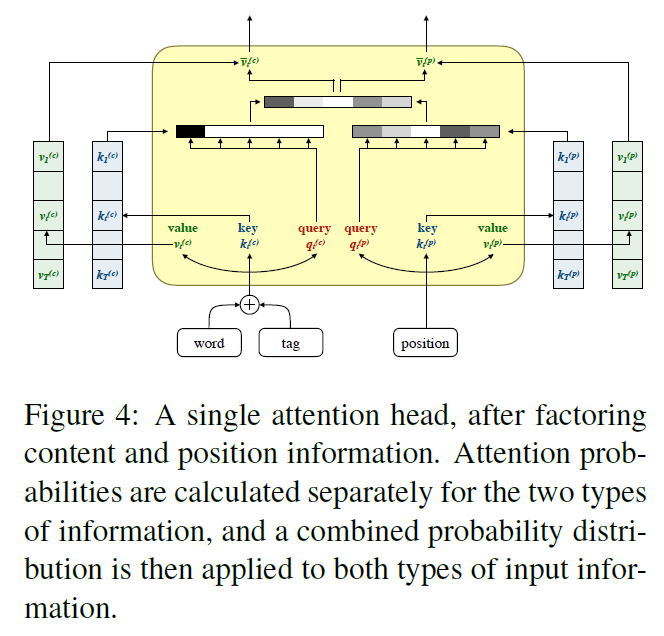 拆分后的 attention head
拆分后的 attention head此外,作者认为也可以将这种拆分看成是在参数矩阵上强制加上块稀疏化(block-sparsity)约束:
就像之前一样,也保持相同的向量大小,也就意味着减少了参数量。简单来说,作者将每个向量都一半一半拆成内容和位置向量,那么就相当于模型参数量减少了一半(???)。最终这个模型在 dev 上达到了 93.15 的 F1,得到了约 0.5 的提升。
这个结果表明拆分不同类型的特征确实能得到一个不错的结果,但是作者还有一个疑惑:也许通过将所有矩阵都进行块稀疏化,我们偶然发现了更好的超参数配置?例如这个结果提升可能只是和模型参数量有关?
为了验证这个猜想,作者又进行了一次实验。控制变量法,这次的模型始终强制进行块稀疏化,但是输入仍然使用原来的 3 个矩阵相加的结果,也就是不拆分内容和位置特征。最后的 F1 是 92.63,和 base 模型差不多(92.67)。这也就证明了 factoring 是很重要的。
正是应了 The Zen of Python 那句话:
Explicit is better than implicit.
两种注意力在不同模型不同层的重要性
随后作者又进一步分析了模型,主要是两部分:对内容和位置注意力的进一步分析和 windowed attention。
为了分析模型对内容和位置注意力的利用情况,作者又做了个实验,模型训练保持不变,但是在测试阶段,把内容注意力或位置注意力人为置零,即禁用。分别在不同的层禁用内容或者位置注意力,最后发现位置注意力相当重要,但是内容注意力也有一定帮助,尤其是在最后几层。结果如下表所示:
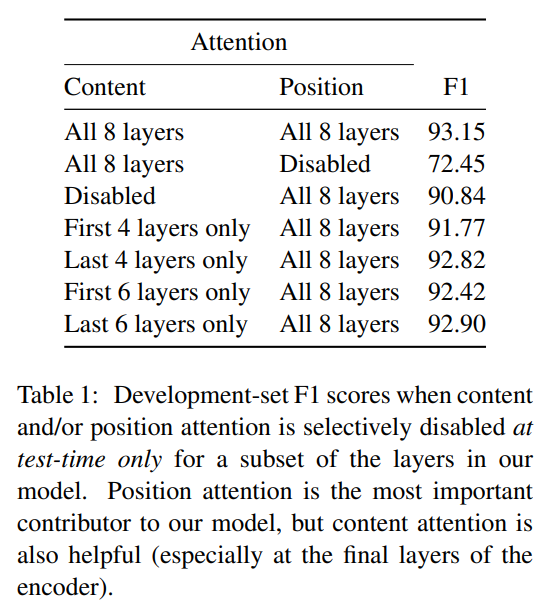 表1
表1同时也可以看到模型确实利用了两种特征,而且位置特征占据主导位置。内容特征在后面几层更有用,同时也验证了作者之前的猜想:模型的前几层就像一个 CNN,更高的层能够更好的平衡两种特征。
是不是同时也表明位置特征是一种浅层特征,而内容特征是一种高层次特征?这也符合我们的直觉。
尝试 Attention 变体:Windowed Attention
关于 windowed attention,首先说下这是什么意思。对于 A 和 B 两句话,原本的注意力机制是两句话中的词互相都有注意力连接,A 中的词注意 B 中所有的词,B 中的词注意 A 中的所有词,就是一个 dense 连接。但是现在 windowed attention 就变成, B 中的词只能注意 A 中的一部分词,而具体多少词,就是 distance。A 对 B 也同理。这种方式叫 strict windowed attention。
有 strict,自然就有不那么 strict 的,即 relaxed windowed attention。这个版本的 windowed attention 主要是由于作者偶然发现有几个 attention head 的某几层总是会 attend to start token,总是会对标记句子开始的特殊标记(不是句子的第一个词)格外的注意。
既然如此,那就来个 relaxed 版的 windowed attention,即一个句子的 start token、第一个词、最后一个词和 end token,不受 window 限制,可以正常与其他词进行注意力连接,相当于加了个特例,条件“宽松”了一些。实验结果如下表所示,结果表明 relaxed 版的模型 F1 更高。作者后来又将 strict 和 relaxed windowed attention 融入到训练过程中,再次实验。
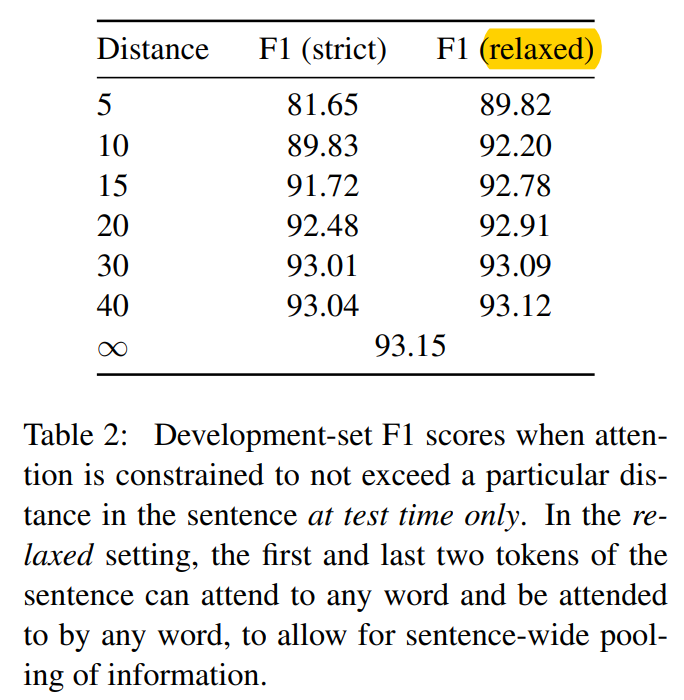 表2
表2进行了这么多实验,最终的结论就是长距离依赖对于取得最佳准确率是必不可少的。
Factored model without/with extra data
回想刚才讲的模型,输入是三个 embedding 相加:word、postag 和 position。其中 postag 是需要事先使用 Stanford tagger 算好的,也就是利用了额外数据。而 word embedding 此时我们并没有使用 pretrained embedding。那么这就诞生了接下来的两个实验:替换 postag,即尽量不使用这种外部数据;使用 pretrained word embedding。
替换 postag embedding
先说第一个。作者首先尝试直接将 postag 去掉,结果发现 F1 直接掉了一个点。然后分别尝试使用 CharLSTM 和 CharConcat 来替代 postag,并且与是否使用 word embedding 进行组合,共四次小实验。结果发现用 CharLSTM、带 word embedding 的效果最好,甚至比原来的使用 postag 的效果还好,CharConcat 效果好于原版,但劣于 CharLSTM。
那么什么是 CharLSTM?
不难,就是使用一个双向 LSTM 来 embed 一个单词,只不过输入是 char 级别的。然后使用 LSTM 的输出来替换 postag。作者还发现,只使用这个,丢掉原来的 word embedding 的效果比用 word embedding 的效果还要好。我觉得这应该很明显吧,CharLSTM 本质上还是一个词的 embedding,再加上一遍 word embedding 只会造成冗余。
那什么是 CharConcat 呢?
你可能是第一次听说,我也是。不过也不难,作者说这是他们从 Hall et al. (2014)4 得来的灵感,Hall 他们是用出现频率较高的后缀来替代词。那么这里类似,就是取一个单词的前后 8 个共计 16 个字母来表示该单词,每个字母的 embedding 是 32 维的,16 个 concat 到一起就变成了 512 维。如果单词太短, 那么就 padding。这种极致简单的模式带来了意想不到的效果,虽然比 CharLSTM 差,但是比原版要好。
又应了 The Zen of Python 的那句话了:
Simple is better than complex.
Pretrained word embedding
现在说第二个,pretrained word embedding 的问题。其实也没啥可说的,作者直接使用了 ELMo,但是 ELMo 的词向量是 1024 维的,而本文模型是 512 维的,对不上怎么办?
Project,学习一个权重矩阵将这个 1024 维的 ELMo 映射到 512 维。作者还认为已经有这么强大的预训练词向量了,encoder 就不需要 8 层了。事实证明没错,最后只要 4 层,在 dev 上就已经达到了 95.21 的 F1。
结果
在 PTB 测试集上最佳 F1 为 95.13,模型为 factored self-attentive + ELMo,即刚才说的最后一个版本的模型。详细的测试结果如下图所示:
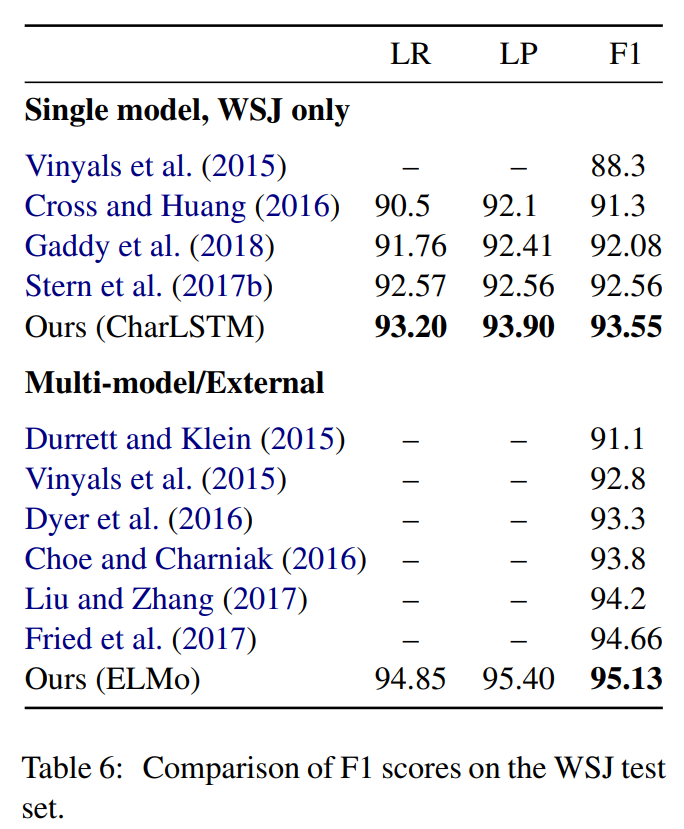 表6
表6作者对自己的模型在其他语言上的表现也很有信心,在包含 9 种语言的数据集 SPMRL 上做了测试,其中 8 种语言达到了 SOTA。详细的测试结果如下图所示:
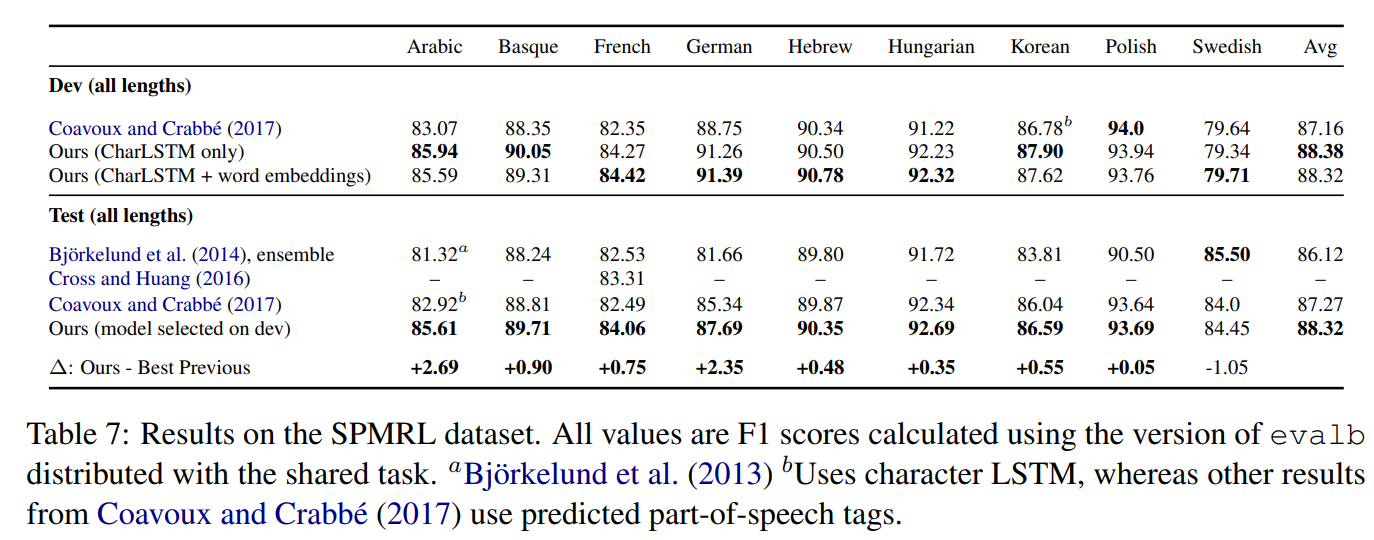 表7
表7END
1. Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017. ↩
2. Stern, Mitchell, Jacob Andreas, and Dan Klein. “A minimal span-based neural constituency parser.” arXiv preprint arXiv:1705.03919 (2017). ↩
3. Gaddy, David, Mitchell Stern, and Dan Klein. “What’s going on in neural constituency parsers? an analysis.” arXiv preprint arXiv:1804.07853 (2018). ↩
4. Hall, David, Greg Durrett, and Dan Klein. “Less grammar, more features.” Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2014. ↩